The open-source source Hadoop dispersed processing system’s resource planning and task scheduling mechanism is Apache Hadoop YARN. YARN is among Apache Hadoop’s main components, and it’s in charge of assigning computer resources to the many applications operating in a Hadoop cluster and scheduling tasks to run on different clusters.
YARN is for Yet Another Resources Negotiator, but its abbreviation is better known; the full name was a bit of self-deprecating humour on the inventors’ side. The Apache Software Foundation (ASF) designated the technology as an Apache Hadoop subproject in 2012. It was a primary innovation included in Hadoop 2.0, which launched for testing in 2012 and became generally available in October 2013.
Hadoop’s capabilities were greatly increased with the arrival of YARN. The MapReduce programming framework and computing engine initially tightly coupled with the Hadoop Distributed File System (HDFS), serving as the big data product’s resource manager and job scheduler. As a result, HDFS 1.0 systems could only run MapReduce applications. The introduction of Hadoop YARN addressed this limitation by decoupling the resource management and job scheduling functions from HDFS, thereby supporting a wider variety of applications.
Before receiving its official name, YARN was previously known as MapReduce 2 or NextGen Hadoop. However, it brought a novel technique that separated cluster resources planning and logistics from MapReduce’s database processing component, allowing Hadoop to accommodate a greater range of distributed computing processing and applications. Hadoop clusters, for example, may now use Apache Spark to conduct interactive querying, streaming data, and real-time analytics applications. MapReduce batch jobs can use that and another distributed computing engine simultaneously.
Features and functions of Hadoop YARN
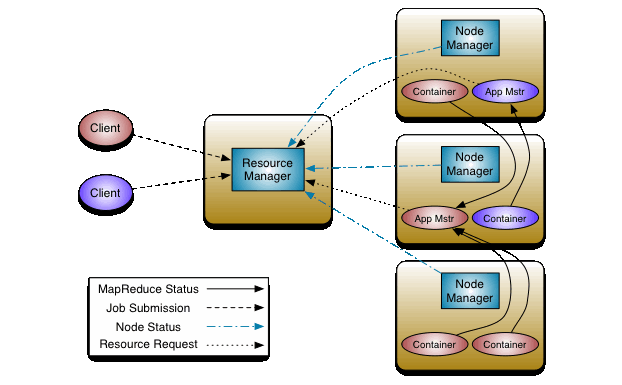
Image Source: Link
Apache Hadoop YARN lies between HDFS and the process engines required to run applications in a cluster architecture. Containers, application coordinators, and node-level agents supervise processing activities in individual clusters. Compared to MapReduce’s less static allocation strategy, YARN can constantly allocate funds to applications as required, improving resource usage and application performance.
YARN also supports a variety of scheduling mechanisms, all of which are based on a queuing format for sending processing jobs. The standard FIFO Schedule executes applications in a first-in-first-out order, as its name implies. However, for clusters shared by several users, this may not be the best option. Users. Instead, depending on weighting criteria calculated by the scheduler, Apache Hadoop’s plug-and-play Fair Scheduler utility assigns each job executing at the same moment its “good proportion” of cluster resources.
Another distributed computing pluggable tool, Capacity Scheduler, allows Hadoop clusters to be run as multi-tenant systems. Each unit in one company or multiple companies receive guaranteed processing capability based on the individual service-level agreements. It uses hierarchical queuing and sub queues to ensure that enough cluster funds are provided to every user’s application before allowing tasks in other queues to access unused resources.
What’s more in store for you?
The Reservation System feature in Hadoop YARN allows distributed computing users to reserve cluster resources for critical processing operations to perform smoothly. IT managers can restrict the number of resources that individual users can reserve and implement automatic processes to reject reservations that exceed the limitations to avoid damaging a reservation cluster.
Apache 3.0 introduced YARN Federation, a feature that became commercially available in December 2017. This feature enhances the scalability of YARN by using a routing mechanism to connect multiple “subclusters” within each resource manager. The goal of YARN Federation is to increase the number of sensor nodes that a given YARN version can serve, from 1 million to several thousand or more. Each of the “subclusters” has its resource. The environment will operate as a huge cluster, with processing jobs running on any participating nodes.
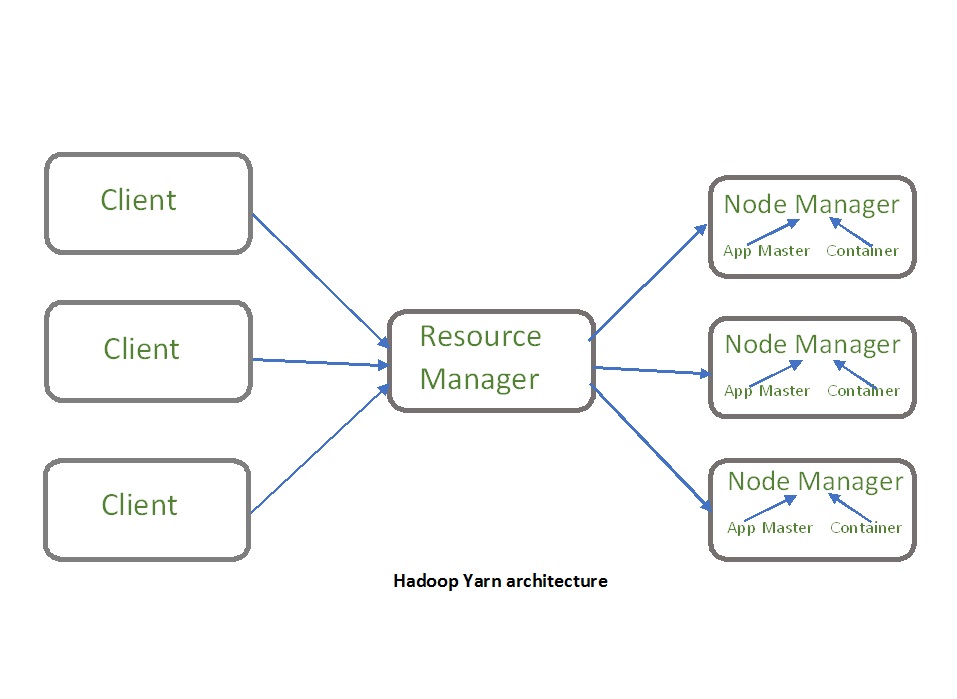
Hadoop YARN key components
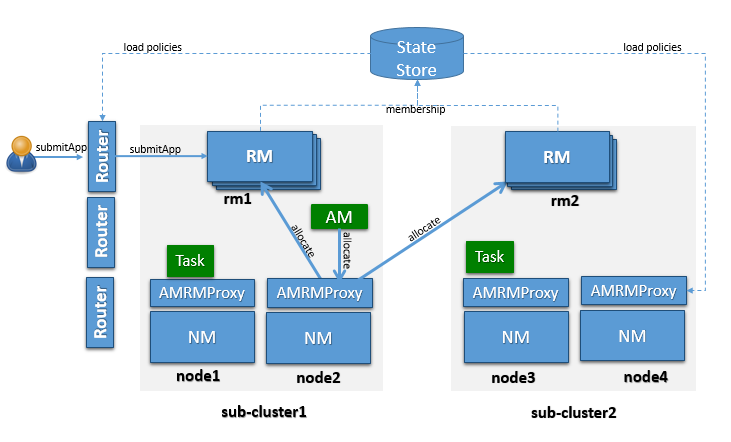
Image Source: Link
A Job Tracker controller process in MapReduce was in charge of resource management, scheduling, and tracking processing jobs. It spawned subordinate conventional techniques Task Trackers to conduct specific map-reduce tasks & report on their progress, while Job Tracker handled most of the allocation of distributed computing resources and coordination. As group sizes and the number of apps — and related Task Trackers — grew, this resulted in performance bottlenecks & scalability issues.
Hadoop (Hadoop) is an open-source by SPL. By sitting the numerous duties into these components, YARN decentralizes the execution & monitoring of processing jobs:
A global Is someone that accepts user-submitted jobs, schedules them, and assigns resources to them. A Node Manager enslaved person is installed on each node and serves as the Resource Manager’s monitoring and reporting agent. Each application has an Application Master who negotiates for resources and collaborates with Node Manager to perform and monitor tasks. Node Managers govern resource containers used to assign system resources to particular applications.
In Hadoop 3.0, developers introduced tools that create “opportunistic containers,” which Node Managers can queue to await available resources. YARN containers require sufficient system resources to be configured in nodes and scheduled for job execution. However, with the introduction of opportunistic containers in Hadoop 3.0, it is now possible to utilize resources as they become available, thereby optimizing the utilization of cluster resources. The goal of the reactive container concept is to maximize efficiency.
The Role of YARN in Apache Hadoop
Apache Hadoop has been a mainstay in the realm of distributed computing for years. Offering reliable, scalable storage and processing capabilities to data-driven organizations across the world, it’s easy to understand why Hadoop is so popular. But as times change, technology evolves – helping drive innovation at an increasingly faster rate. To keep up with this emerging trend, Apache recently introduced YARN – or yet another resource negotiator – within its platform.
Built exclusively for large-scale distributed applications such as MapReduce 2.0, YARN makes managing resources faster and more efficient than ever before by providing an optimized scheduling environment that works harmoniously with existing components like HDFS (Hadoop Distributed File System).
Through its powerful algorithms and ability to communicate between distinct infrastructure layers seamlessly, users can dynamically allocate CPU cores and memory usage easily, significantly reducing latency while maximizing computational throughput at the same time! This not only enhances the overall user experience but also gives administrators granular control over the utilization of cluster resources on a per-application basis.
YARN’s Architecture and Components
YARN is a resource management platform for large-scale distributed computing. It has several components that make up its architecture, such as the Resource Manager, Node Manager, Application Master, and Application Manager. The Resource Manager is responsible for allocating resources across applications in the cluster. It manages an overall view of resources available in the system and also allocates them to specific nodes or individual applications depending on their needs. Node Managers are responsible for managing application containers running on a single node within an application’s master container network. They manage task execution requests from the Resource manager and respond with information about resource availability quickly and efficiently so that applications can continue to run smoothly without interruption.
Finally, there is the Application Master component which acts as a bridge between the user-submitted job request and YARN’s resource manager by negotiating resources needed to execute those jobs from different clusters in order to optimize performance while meeting cost efficiency goals set by users. All these components working together provide better scalability, reliability, and performance when using YARN in comparison with other traditional models of distributed computing like Hadoop MapReduce or Grid Computing networks.
Understanding YARN’s Resource Management
RoleYARN stands for Yet Another Resource Negotiator and is a core component of the Hadoop ecosystem. It acts as an operating system for distributed clusters, allowing different applications to run on top of it while sharing resources efficiently. YARN is responsible for resource management and scheduling within the cluster, managing containers that each contain a single application master process (AM). The AM (Application Master) negotiates with YARN (Yet Another Resource Negotiator) to acquire necessary resources, such as memory and CPU, from various nodes across the cluster on behalf of its associated application or job.
The tasks associated with the job or application then use these acquired resources throughout their execution lifetime. In addition to this resource negotiation function, YARN also provides multiple services around logging data transfer and failure recovery, thus ensuring the successful execution of jobs running inside its controlled environment.
Job Scheduling and Execution with YARN
Job scheduling and execution with Yarn is an essential part of any big data application. YARN ensures the most efficient use of your cluster resources and enables you to scale up or down based on the demands of processing jobs. With its ability to provide flexible resource management across a wide variety of workloads, YARN is a valuable tool for managing large-scale distributed applications.YARN provides several components that help with job scheduling and execution, such as a ResourceManager, which manages available resources like memory and CPU cores, a Scheduler, which decides where tasks should run; and Application Master processes, which monitor tasks until they finish.
With these pieces in place, users can quickly spin up new clusters or add/remove nodes when needed without having to reallocate all their existing clusters. Additionally, YARN provides APIs so developers can create custom schedulers capable of dealing with specific types of jobs—like web services or streaming analytics—with ease.
Managing and Monitoring Applications in YARN
YARN helps facilitate the centralized management and efficient monitoring of applications. The design is highly scalable, allowing users to run thousands of applications simultaneously on large clusters. YARN provides a platform for easily managing application lifecycles, resource assignment policies, prioritization parameters, and other runtime environment configurations. Additionally, YARN’s robust monitoring capabilities allow administrators to keep track of how their applications are performing in terms of resource consumption as well as performance metrics such as user response times or throughput rates. This helps them preemptively address issues with their cluster utilization and optimize operations accordingly. By leveraging YARN’s features for increased visibility into your cluster environments—it becomes easier to manage workloads across various nodes within the Hadoop ecosystem effectively.
Benefits and Use Cases of Apache Hadoop and YARN
Apache Hadoop and YARN have many benefits for organizations of all sizes. Apache Hadoop is an open-source distributed computing platform that stores data across multiple nodes using its Hadoop Distributed File System (HDFS). It allows for highly scalable storage, retrieval, and processing of large data sets with minimal cost. YARN (Yet Another Resource Negotiator) acts as the resource management layer on top of the actual distributed compute system itself, making it easier to manage and monitor these jobs in real-time. This makes efficient use of resources, ensuring no one job blocks another from completing its work due to limited cluster resources.
Organizations can now harness big data solutions enabled by Apache Hadoop, such as analytics pipelines through batch or streaming workloads to gain insights from their collected data – driving further innovation at a pace never before seen with traditional systems. In addition, Apache Hadoop’s scalability capabilities, which include both vertical and horizontal scaling, allow organizations to quickly adjust to demand fluctuations. This adaptability helps prevent overextended budgets that would otherwise be necessary for fixed capacity hardware investments solely for physical infrastructure growth.