What is the purpose of GPFS?
![PDF] File Systems and Storage on Making Gpfs Truly General the Basics Where He Serves as a Technical Leader of the Parallel File Systems Group and Principal Architect of Ibm's General Parallel](https://d3i71xaburhd42.cloudfront.net/84ff5931051ff905b313669415e10e068d1c9ee9/2-Figure1-1.png)
The IBM General Parallel File System (IBM GPFS) is a file system that you can use in numerous high-performance computing and large-scale storage surroundings. You can use it to disperse and manage data from multiple servers. GPFS is one of the most widely popular file systems for elevated computing (HPC) apps.
More data is being generated, analyzed, and stored by businesses and organizations than ever. Representatives in their industry are those who can deliver amazing ideas while managing rapid infrastructure expansion. To provide those insights, an institution’s underlying storage must endorse new era, big-data apps, and traditional apps with high performance, serviceability, and safety. Stockpiling must scale seamlessly to manage massive disparate data growth while matching data points to the capabilities and costs of various storage tiers and kinds. IBM Spectrum Scale fulfills all of these requirements and more. It is a high-performance parallel file system to manage data at scale, with the unique ability to perform in-place records and analytics.
IBM Spectrum Measure is an enterprise-grade distributed processing system. It provides outstanding resiliency, expandability, and control as part of the IBM Spectrum Storage family of remedies. IBM Spectrum Scale, built on the IBM General Parallel File System (GPFS), provides scalable performance and effectiveness for demanding data analytics, information repositories, and technical computing work overload. Storage administrators can merge flash, disc, cloud, and tape storage into a universal platform that is faster and less expensive than traditional methods. IBM Spectrum Scale is a file system that can adjust to software performance and stability needs across the organization, with thousands of clients and nearly 20 decades of demanding production deployments.
What’s more to it?
Institutions can simplify data workflow processes, improve the service, cut prices, manage risk, and produce business results while placing the enterprise for growth prospects by incorporating IBM Spectrum Scale into their software-defined facilities. IBM Spectrum Scale combines virtualization, predictive analysis, file, and object space into a solitary scale-out storage medium. It could provide a single identifier for all this information, providing a centralized management functionality with an intuitive graphical user interface (GUI). You can compress the information or layer it to tape or cloud to help reduce expenses. You can also layer the information to the high-performance mainstream press. This includes backend cache, to lower latency and boost efficiency, using transparent memory policies to target consumers.
Information management at scale has been simplified

IBM Spectrum Scale is a concurrent file system in which the intelligence is in the customer. The customer distributes the burden across all memory nodes in a cluster, even for single files. In conventional scale-out network-attached storage (NAS), an individual client can only connect one document simultaneously through one node, restricting flexibility and efficiency. In comparison, the IBM Spectrum Scale architecture allows it to manage tens of hundreds of individuals, billions of files, as well as yottabytes of data with ease.
IBM Spectrum Scale enables multiple services and applications to obtain the same information without needing to relocate or modify it. Information can be stored and recovered as files or items. Rather than using a copy and transformation gateway, IBM Spectrum Scale supports both file protocols for improved performance and easier management. Most IBM Spectrum Scale features, such as verification, encryption, and tiering, enables by the common storage layer for both objects and file storage.
What makes IBM unique?
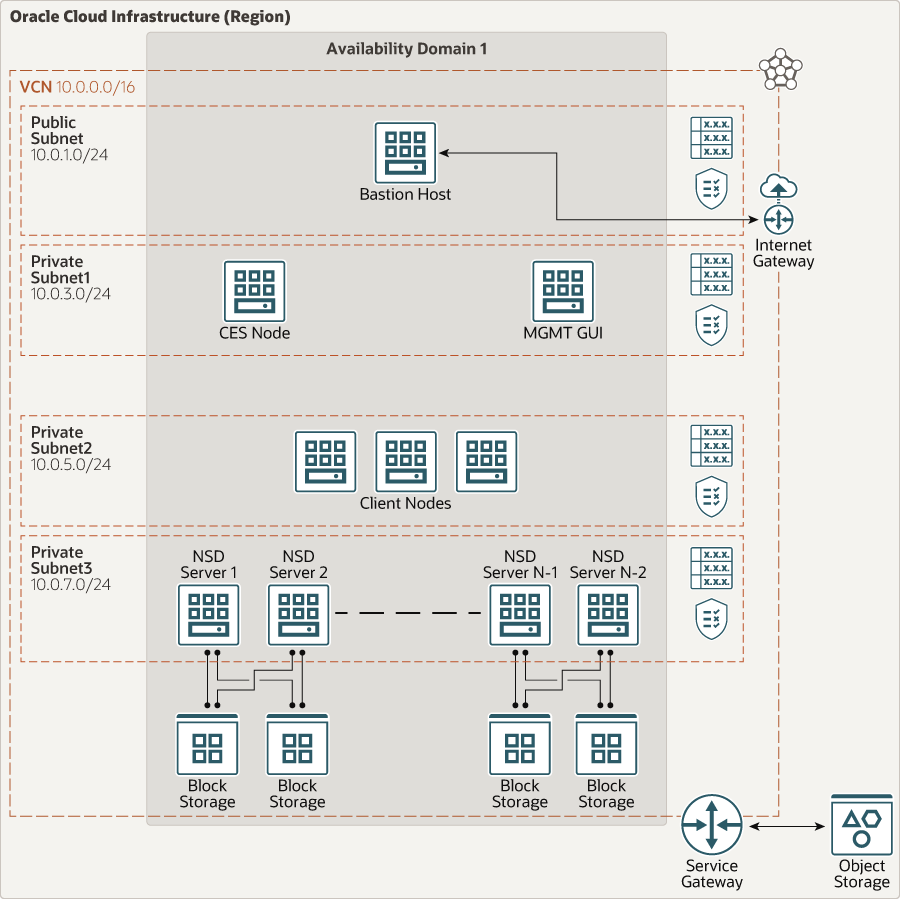
The IBM Spectrum Scale message is straightforward. The high-performance parallels data connectivity with enterprise information services connecting margin to core to cloud platform in a single cluster. IBM Spectrum Scale is a market-leading storage solution for AI, predictive analysis, high-performance computing, and any high-performance or high-capacity file storage volume of work.
A hybrid cloud-based data revitalization strategy is more than just a product.
IBM Spectrum Scale has a straightforward message: Safe access. Anyplace. Data services for businesses. Everywhere. Cloud hybridization. Anyone. IBM Spectrum Scale is the hub of IBM Storage for Data and AI information systems. It is a worldwide hybrid cloud storage device with concurrent access. It is the glue in creating a hybrid cloud storage solution for any venture or organization’s AI technology architecture.
Spectrum Scale by IBM in the Public Cloud
IBM Spectrum Scale is accessible in the AWS marketplace and contains supported reference architectures. IBM Spectrum Scale on AWS is configured for high-performance applications like AI. You can tailor it with various storage solutions, including the ESS 5000, ESS 3000, and other IBM Spectrum Scale configurations.
FAQs
What is GPFS for high availability and high-performance cloud?
GPFS (General Parallel File System) for high availability and high-performance cloud is a distributed file system designed to ensure reliable and efficient data storage and access in cloud environments. It offers features such as data replication, automatic failover, and scalable performance to meet the demands of cloud-based applications and services.
How does GPFS ensure high availability in the cloud?
GPFS ensures high availability in the cloud by replicating data across multiple storage nodes or geographic locations. In the event of a hardware failure or network outage, GPFS can automatically failover to secondary copies of data, ensuring continuous access and minimizing downtime.
What are the benefits of using GPFS for high-performance cloud environments?
Using GPFS in high-performance cloud environments offers several benefits, including improved scalability to handle large volumes of data, enhanced performance for data-intensive workloads, and seamless integration with cloud platforms and services. GPFS also provides advanced data management capabilities such as snapshots, data tiering, and data compression.
How does GPFS optimize performance in the cloud?
GPFS optimizes performance in the cloud by leveraging parallel I/O, data striping, and caching techniques to distribute data processing tasks across multiple nodes and storage devices. This enables GPFS to deliver high throughput and low latency for data access, even in highly distributed cloud environments.
What are the key features of GPFS for high availability and high-performance cloud?
Key features of GPFS for high availability and high-performance cloud include support for distributed storage architectures, automatic data replication and failover, dynamic storage tiering, integration with cloud storage services, and advanced data management and security capabilities.
How can GPFS be deployed in cloud environments?
Deploying GPFS in cloud environments involves installing GPFS software on cloud instances or virtual machines. It also configures storage nodes and networking, and integrates GPFS with cloud management platforms and services. IBM provides tools and documentation to facilitate the deployment and management of GPFS in cloud environments.
What support and resources are available for GPFS in the cloud?
IBM offers comprehensive support and resources for GPFS in the cloud. This includes technical documentation, training courses, online forums, and dedicated support services. Organizations can leverage these resources to deploy, optimize, and manage GPFS deployments in cloud environments effectively.