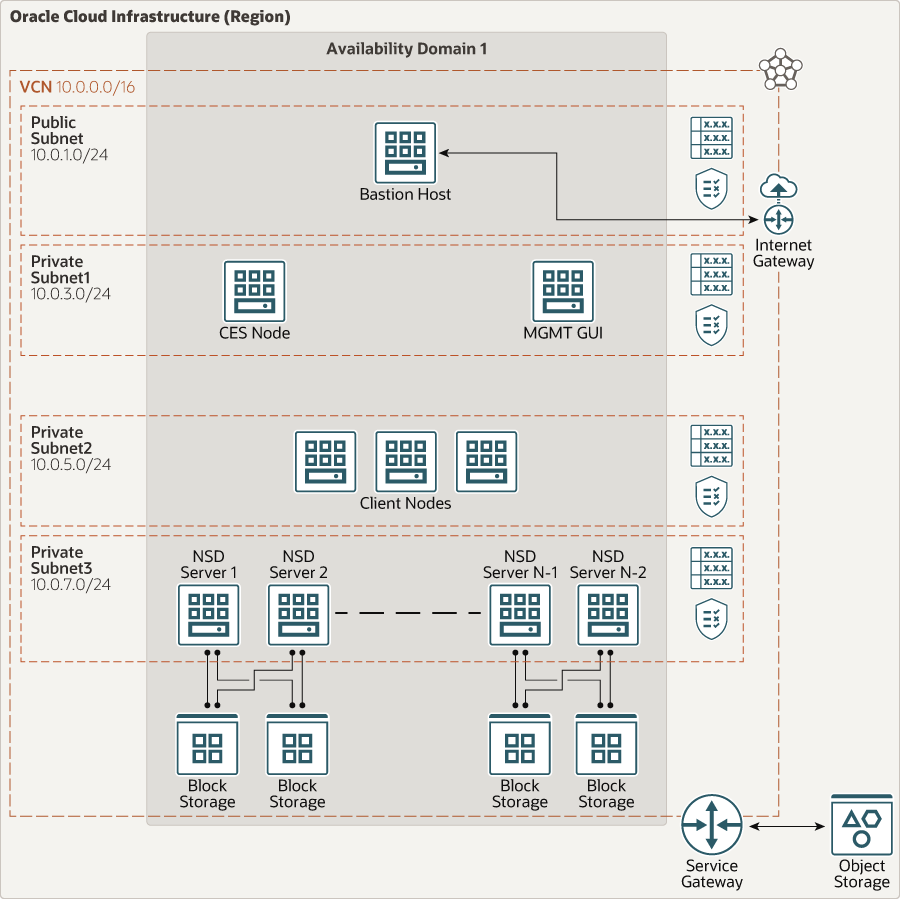
IBM General Parallel file system (IBM GPFS) is a document system that you can use to distribute and control information throughout more than one server. You can implement it in much high-overall performance computing and massive-scale storage environments.
GPFS Memory is most of the leading document structures for high-performance computing (HPC) applications. You can use a Garage for big supercomputers that is regularly GPFS-based. GPFS is also famous for industrial programs requiring high-pace entry to large volumes of facts, consisting of virtual media, seismic facts processing, and engineering layout.
Structure of GPFS Network Operations:
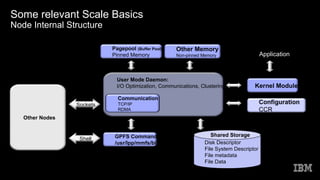
Interaction between nodes at the file machine stage is limited to the locks and control flows required to preserve records and metadata integrity inside the parallel surroundings.
A discussion of GPFS Memory consists of the following:
• unique control functions
In trendy, GPFS performs identical functions on all nodes. It handles utility requests at the node in which the utility exists. This provides maximum affinity of the facts to the software.
• Use of disk garage and report shape within a GPFS record machine
A report machine includes a set of disks that save record statistics, file metadata, and helping entities such as quota documents and recuperation logs.
• GPFS and reminiscence
GPFS Memory uses three areas of reminiscence: reminiscence allocated from the kernel heap, memory allocated inside the daemon phase, and shared segments accessed from each daemon and the kernel.
• GPFS and network communication
In the GPFS cluster, you may specify one-of-a-kind networks for GPFS daemon communique and GPFS command usage.
• software and user interaction with GPFS
There are 4 approaches to interacting with a GPFS Memory and Network Operations
• NSD disk discovery
While the GPFS daemon starts offevolved on a node, it discovers the disks defined as nsds by analyzing a disk descriptor written on each disk owned by GPFS. This allows the nsds to be determined regardless of the modern-day operating gadget tool name assigned to the disk.
• Failure in healing processing
GPFS failure recovery processing occurs automatically. Therefore, even though no longer important, a few familiarities with its internal features are useful while failures are found.
• Cluster configuration facts files
GPFS Memory commands store configuration and document gadget records in one or more files, known as GPFS cluster configuration facts files.
• GPFS backup facts
The GPFS command creates several documents for the duration of command execution. A number of the files are brief and deleted upon the cease of the backup operation.
• Cluster configuration repository
The cluster configuration repository (CCR) of IBM Spectrum Scale is a fault-tolerant configuration shop used by almost all IBM Spectrum Scale additives, together with GPFS, GUI, device fitness, and Cluster Export services (CES) to call some.
• GPU Direct storage guide for IBM Spectrum Scale
IBM Spectrum Scale’s help for NVIDIA’s GPU direct garage (GDS) enables a direct direction between GPU memory and storage. This answer addresses the need for higher throughput and decreased latencies. Report machine storage is directly connected to the GPU buffers to reduce latency and cargo on the CPU.
GPFS and memory
It uses three regions of reminiscence: memory allotted from the kernel heap, reminiscence allocated in the daemon segment, and shared segments accessed from each daemon and the kernel..
GPFS and memory from the kernel heap
It uses kernel reminiscence to manipulate structures which include nodes and associated systems that set up the essential courting with the running system.
Reminiscence is allotted inside the daemon segment.
GPFS uses daemon segment memory for file device supervisor capabilities. Because of that, the report gadget supervisor node calls for more daemon memory when you consider that token states for the entire document device are, to begin with, saved there. Document gadget manager functions requiring daemon memory include:
- Structures that persist for I/O operations
- States related to different nodes
The report device supervisor is a token, and other nodes might also anticipate token management responsibilities; consequently, any supervisor node may consume extra memory for token management. For extra statistics, see the usage of more than one token server in IBM Spectrum Scale: advanced administration guide.
Shared segments accessed from each daemon and the kernel
Shared segments include pinned and unpinned reminiscence allocated at daemon startup. The preliminary values are the device defaults. However, you may alternate these values later with the much config command. See Cluster configuration document.
The pinned memory is the page pool and is configured by setting the web page pool cluster configuration parameter. This pinned vicinity of memory is used for storing document records and for optimizing the overall performance of various information get entry to patterns. In a non-pinned vicinity of the shared segment, GPFS continues to record open and currently opened documents. This fact is held in two forms:
- A complete inode cache
- A stat cache
GPFS (General Parallel File System), developed by IBM, is a high-performance, shared-disk file system designed to handle large-scale data storage and processing across distributed computing clusters. Memory and network operations play a critical role in the performance and scalability of GPFS. In this article, we will explore the significance of memory and network operations in GPFS and how they contribute to its efficiency and effectiveness.
Memory in GPFS
Memory management is crucial for optimizing the performance of GPFS. GPFS uses memory in various ways to enhance its operations:
- Metadata Caching: GPFS employs metadata caching to improve file system performance. Metadata, such as file attributes, directory structures, and access control information, is cached in memory to reduce the need for disk access during file system operations. Caching metadata in memory allows for faster retrieval and manipulation of file system metadata, leading to improved overall system performance.
- Buffer Cache: GPFS utilizes a buffer cache to optimize data read and write operations. The buffer cache holds frequently accessed data blocks in memory, reducing the need for disk I/O operations. By keeping data blocks in memory, GPFS can satisfy read requests directly from the cache, minimizing latency and improving data access speeds.
- I/O Caching: GPFS employs I/O caching techniques to enhance data throughput and reduce disk I/O operations. Data that is read or written to disk is temporarily cached in memory, allowing subsequent read or write operations to be satisfied from the cache rather than accessing the disk. I/O caching improves overall I/O performance and reduces the wear and tear on physical storage devices.
- Metadata Replication: GPFS can replicate metadata across multiple nodes in a cluster. Replicating metadata in memory ensures high availability and fault tolerance. If a node fails, the replicated metadata can be used to continue file system operations without interruption, minimizing downtime and ensuring system reliability.
Network Operations in GPFS
GPFS utilizes network operations to enable communication and data transfer between nodes in a distributed computing cluster. The network operations in GPFS contribute to its scalability and performance:
- Data Transfer: GPFS relies on network operations to transfer data between nodes in the cluster. Large-scale data transfers are facilitated through high-speed network connections, allowing for efficient and parallel data movement across multiple nodes. GPFS leverages network bandwidth to achieve optimal data transfer rates, enhancing overall system performance.
- Metadata Exchange: GPFS uses network operations for exchanging metadata between nodes in the cluster. Metadata, such as file attributes and directory structures, needs to be synchronized across all nodes to ensure consistent file system operations. Network communication enables efficient metadata exchange, ensuring that all nodes have up-to-date information about the file system’s structure and attributes.
- Cluster Management: GPFS employs network operations for cluster management tasks, such as node discovery, load balancing, and failover handling. Network communication enables nodes to coordinate and collaborate effectively, distributing workload and maintaining system stability. GPFS utilizes network protocols and algorithms to optimize cluster management operations, ensuring efficient resource utilization and fault tolerance.
- Network Security: GPFS incorporates network security measures to protect data during network operations. Secure communication protocols, encryption, and authentication mechanisms are employed to safeguard data integrity and confidentiality. Network security measures help mitigate the risk of unauthorized access, data interception, or tampering during data transfers and metadata exchanges.
Optimizing Memory and Network Operations in GPFS
To optimize memory and network operations in GPFS, you can follow several best practices:
- Memory Allocation: Proper memory allocation is crucial for GPFS performance. You should allocate sufficient memory for metadata caching, buffer cache, and I/O caching to ensure efficient data access and manipulation. Properly sizing the memory allocations based on workload characteristics and system requirements is essential for optimal performance.
- Network Bandwidth: GPFS performance heavily relies on network bandwidth. Deploying high-speed networking infrastructure, such as Ethernet or InfiniBand, can significantly improve data transfer speeds and reduce latency. Ensuring sufficient network bandwidth and minimizing network congestion through network optimization techniques can enhance overall GPFS performance.
- Network Topology: The network topology within the GPFS cluster should carefully design to minimize communication latency and maximize data transfer rates. Employing a well-structured network topology, such as a high-speed, low-latency interconnect, ensures efficient communication between nodes and reduces network bottlenecks.
- Monitoring and Optimization: Regularly monitoring memory usage, network performance, and GPFS metrics is important for identifying potential bottlenecks or performance issues. Monitoring tools can provide insights into memory utilization, network bandwidth, and GPFS performance indicators, allowing administrators to optimize resource allocation and resolve any bottlenecks that may impact system performance.
Conclusion
Memory and network operations are vital components of GPFS, contributing to its performance, scalability, and reliability. Efficient memory management, including metadata caching, buffer cache utilization, and I/O caching, improves data access speeds and overall system performance. Network operations, such as data transfer, metadata exchange, and cluster management, enable efficient communication and collaboration between nodes in a distributed GPFS cluster. By optimizing memory allocation, network bandwidth, and network topology, organizations can ensure optimal GPFS performance, enhance data processing capabilities, and maximize the scalability of their data storage and management infrastructure.
FAQs
What is GPFS memory usage?
GPFS memory usage refers to the amount of memory consumed by the General Parallel File System (GPFS) for various operations such as file I/O, metadata management, and caching. It plays a critical role in system performance and scalability.
How does GPFS manage memory?
GPFS employs memory management techniques to efficiently utilize system resources and optimize performance. This includes dynamic allocation and deallocation of memory based on workload demands, as well as caching frequently accessed data to improve access times.
What factors affect GPFS memory usage?
Several factors influence GPFS memory usage, including the size and complexity of the file system, the number of concurrent operations, the amount of metadata stored, and the configuration of caching and buffering parameters.
How can GPFS memory usage be optimized?
GPFS memory usage can be optimized through proper system configuration, tuning memory parameters based on workload characteristics, and implementing caching strategies to reduce disk I/O and improve performance.
What are GPFS network operations?
GPFS network operations involve data transfer and communication between nodes in a GPFS cluster over a network. These operations are essential for distributed file access, data replication, and synchronization across cluster nodes.
How does GPFS handle network operations?
GPFS utilizes a distributed architecture to manage network operations efficiently, leveraging parallelism and load balancing techniques to distribute data transfer tasks across cluster nodes. It also employs network protocols such as TCP/IP and RDMA for reliable and high-performance communication.
What factors influence GPFS network performance?
Several factors impact GPFS network performance, including network bandwidth, latency, congestion, and the efficiency of network interfaces and switches. Optimizing network configuration and tuning GPFS parameters can help enhance network performance and throughput for better overall system efficiency.