You almost always utilize a file system when you use a computer. The functioning system’s File System unit offers an intuitive interface for accessing data without requiring you to recollect where your information physically dwells on the hard disc (track, sector number, etc.). In any file system, 3 important abstractions are at work.
- File –Although the information may not be stored in the same location on the disk, the end user can still treat the document as a long chain of contiguous bytes.
- Filename – You can obtain your file using an intuitive name such as doc01.txt rather than recalling any physical memory data.
- Directory Tree – These are canisters that aid in organization.
A Brief Overview of NFS as well as PFS

Sun Microsystems, Inc. created NFS (Network File System), a file system that works on a client-server system. It allows users to create files with a network as if they were in a local file folder. This is achieved through extracting (the process whereby an NFS server grants remote clients the ability to connect to its files) and rising processes.
A distributed file structure is a Parallel File System. The information set is divided into blocks, then dispersed across multiple storage devices. To facilitate information exchange, the system employs a global namespace. Parallel File Systems frequently use a devoted server to host metadata, and data is read/written to numerous storage devices concurrently using numerous I/O paths.
Traditionally, parallel file systems were designed for high-performance computing (HPC) surroundings that required access to large documents, massive amounts of data, or concurrent access from numerous compute servers. Based on its General Parallel File System (GPFS), IBM’s Spectrum Scale and the free software Lustre file system are two notable examples of parallel data files.
The following section distinguishes NFS and PFS based on various characteristics:
Bandwidth of I/O
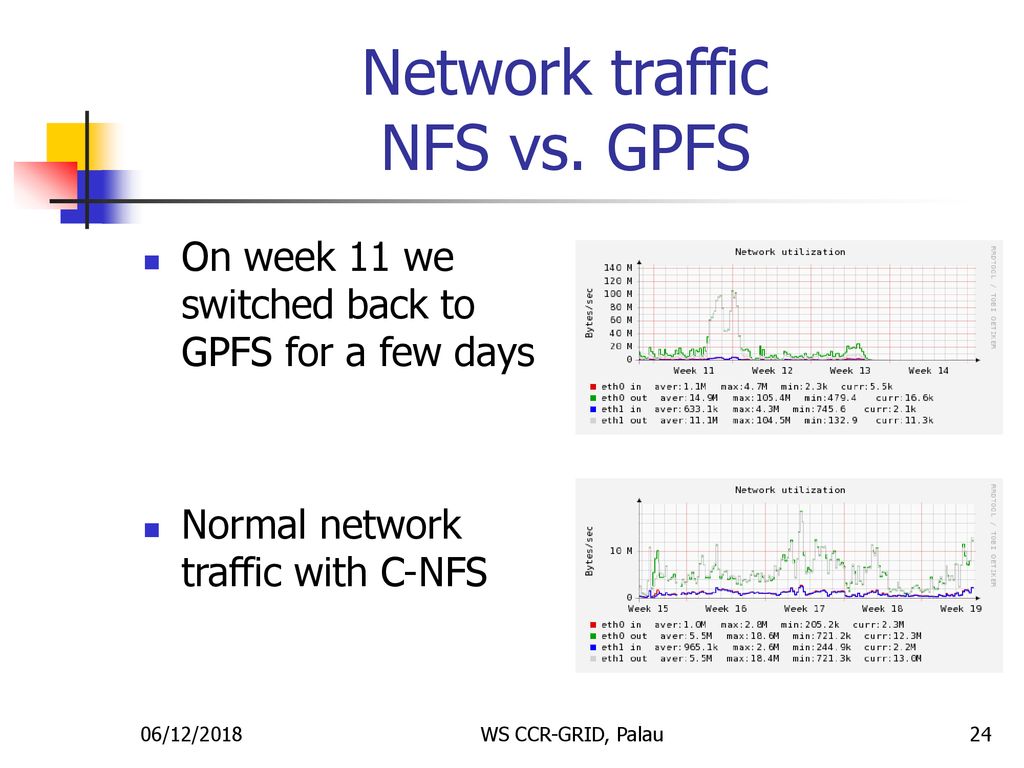
I/O demands made to file system servers by a linear file system are typically the size of the I/O invitation from the proposal, which for the two biggest file systems in terms of market capitalization can be more than 1 MiB and, from one particular instance, up to 16 MiB.
Metadata
Metadata efficiency is frequently a bottleneck in NFS file systems. A few of the features available in parallel file systems are not supported by the underlying NFS protocols, such as performing an ls –l (e.g., stat()) on a directory containing 500,000 files.
Parallel file systems are typically designed to support gazillions of files with excellent performance metadata connectivity. Unlike NFSv3 file systems, they have their metadata synchronized and POSIX-compliant. They support stat() calls from clients at a rate of at least 30,000 stat() demands per second. The parallel file system has about 25,000 open/creates for every second capacity, whereas NFS has much less.
Maintenance
The NFS client and server are much less difficult to set up and maintain. The debugging tools are sophisticated. GPFS incurs significantly higher infrastructure and maintenance costs compared to other distributed file systems due to its usage in High-Performance Computing (HPC) environments.
Scalability
The performance of NFS IO does not scale. It remains an in-band protocol. The data is sent in the same signal as the invitation and is, in practice, limited in number. Reads are more configurable than writes; a popular file segment can be satisfactory from the cache on reads but eventually fails. NFS3 and NFS4 directly support write-behind so that a customer does not have to queue for information to be written to disc, but this is insufficient.
Structure of the Network
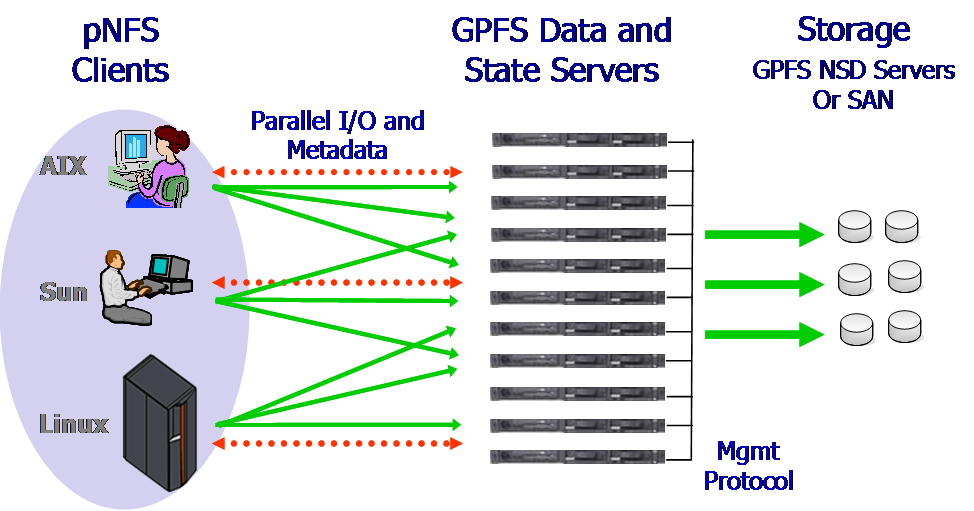
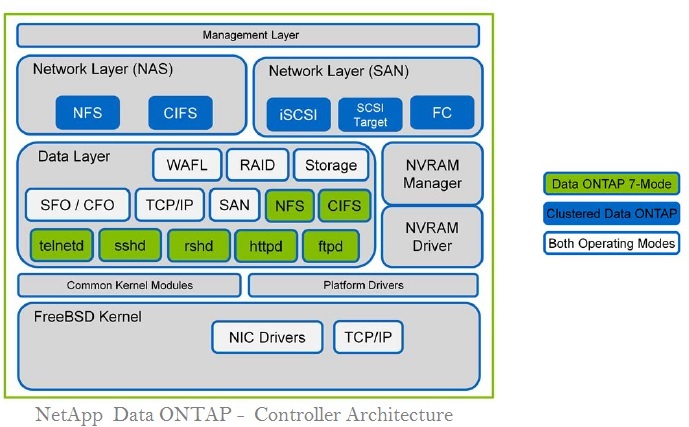
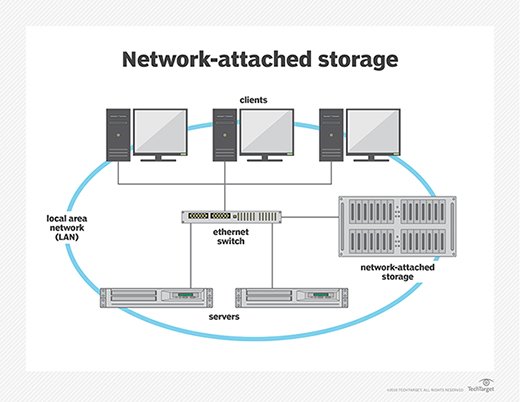
In the most basic case, NFS’s physical discs are formatted as ext3/4 and transferred from the server. Using an NFS client, your desktop computer can mount this file system. Client and server elements are distributed across multiple entities. A distributed file system consists of a single server with a disc and customer. Both NFS, as well as CIFS (SMB), are dispersed file systems that use a single server with different customers.
PFS is created by combining several discrete components, multiple aspects of servers, and discs, to provide a cohesive namespace. The physical boundaries that comprise the file system are unknown to the client. A clustered file system is a distributed file system accessed via a network.
In a nutshell, a distributed file system provides the following benefits:
- Maps well to Unix VFS semantics and is relatively simple to implement (except for caching)
- Reducing the file protocol to its bare essentials makes it more understandable.
- Uses the ONC-RPC authentication model for free and effective security.
And the benefits of the Parallel file system are as follows:
- It is extremely scalable.
- Data replication is supported, as is policy-based storage management.
- Increases throughput for large data requirements.
- High-performance computing requires good performance.
- Is it stable and tried?
FAQs
What is the difference between GPFS and NFS?
Both GPFS (General Parallel File System) and NFS (Network File System) function as file systems utilized for distributed storage, yet they feature distinct architectures and serve different purposes. GPFS is a clustered file system specifically designed for high-performance computing environments. Conversely, NFS serves primarily as a distributed file system utilized for networked file sharing in client-server environments.
How does GPFS differ from NFS in terms of architecture?
GPFS follows a shared-disk architecture, allowing multiple nodes to access shared data stored on a centralized storage device. In contrast, NFS employs a client-server architecture, where clients access files stored on remote servers over a network using NFS protocols.
What are the key features of GPFS compared to NFS?
GPFS offers features such as high performance, scalability, data replication, and dynamic storage tiering, making it suitable for high-performance computing and enterprise storage environments. On the other hand, NFS provides features such as file sharing, access control, and interoperability with different operating systems, making it ideal for networked file sharing and collaborative work environments.
How does GPFS optimize performance compared to NFS?
GPFS optimizes performance through parallel I/O, data striping, and caching techniques, allowing for high throughput and low latency access to data. It is well-suited for data-intensive workloads and applications requiring fast access to large datasets. NFS, while efficient for file sharing, may not offer the same level of performance as GPFS for high-performance computing tasks.
What are the use cases for GPFS and NFS?
In high-performance computing environments, scientific research, financial services, and enterprise data centers, GPFS commonly plays a critical role where performance, scalability, and data integrity are crucial. Conversely, various industries widely utilize NFS for networked file sharing, collaborative work environments, and serving files to client systems.
How does data replication and fault tolerance differ between GPFS and NFS?
GPFS utilizes automatic data replication and mirroring techniques to ensure data redundancy and fault tolerance, protecting against hardware failures and data loss. NFS, on the other hand, relies on redundancy and fault tolerance mechanisms at the storage device or server level, and may not offer the same level of data replication and fault tolerance capabilities as GPFS.
What considerations should be taken into account when choosing between GPFS and NFS?
When choosing between GPFS and NFS, factors such as performance requirements, scalability, data integrity, fault tolerance, interoperability, and cost should consider. Organizations should evaluate their specific needs and use cases to determine which file system best suits their requirements.