Apache Hadoop is a Java-based programming model & decentralized data processing system that is open-source and free. It helps you divide down Big Data analytics computing workloads into smaller chunks. An algorithm is used to run these tasks in parallel. But the same thing happens when a Hadoop cluster is used.
A Hadoop structure is a group of computers that simultaneously handle large amounts of data. These aren’t the same as other computer clusters. The design of Hadoop clusters helps in storing, managing, and analyzing enormous amounts of data. You can structure and unstructured this data within a distributed computer ecosystem. Distributed computing Hadoop ecosystems are also distinct from conventional computer clusters in that they have a distinct structure and architecture. Clusters of Hadoop also include a network with both enslaver & agent nodes. Within it, there is wide availability and low-cost, basic hardware.
Furthermore, we require distributed computing software to work with dispersed systems. The software should manage and coordinate various processors and devices within the distribution ecosystem. As companies like Google grew larger, they began to develop new software. This most recent version is designed to work on all distributed systems.
Cluster Architecture for Hadoop
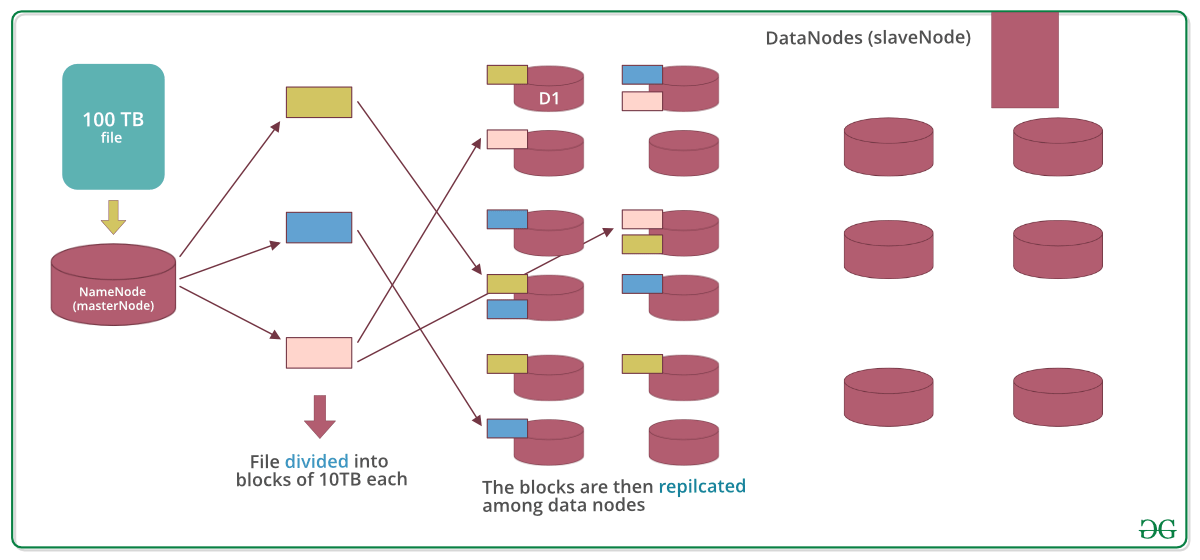
Image Source: Link
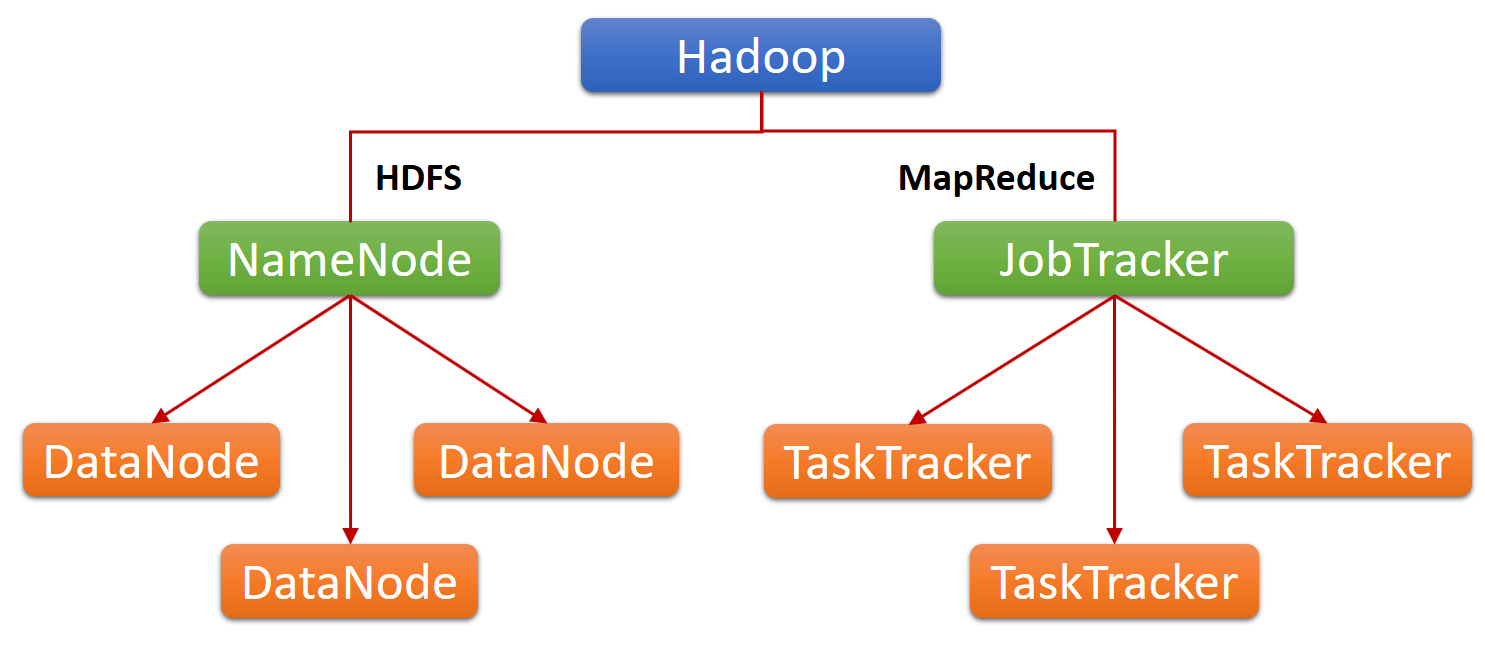
A master-slave architecture is used in Hadoop clusters. It’s defined as a network between master & worker nodes that coordinate and execute various operations across the HDFS. The controller nodes in the Hadoop filesystem often uses high-quality hardware. This consists of a Data node, Task Scheduler, and JobTracker, each running on its machine. Virtual machines (VMs) running both DataNode & TaskTracker applications on distributed computing commodity hardware make up the worker nodes. Under the direction of the controller nodes, they do the work of data storage and processing numerous tasks. The Client Nodes are the final component of the HDFS system. These are in charge of loading data and obtaining outcomes.
The various components of the distributed computing Hadoop cluster design are mentioned below:
Nodes that serve as masters
These are in charge of storing data in HDFS and managing critical processes such as using MapReduce to perform parallel computations on the data.
MapReduce
![HDFS (Hadoop Distributed File System) - Distributed Computing in Java 9 [Book]](https://www.oreilly.com/api/v2/epubs/9781787126992/files/assets/9eb4d5de-9d4f-4ff4-a1aa-711defeb5b95.png)
Image Source: Link
The real data from the HDFS store is processed extensively in this Google-built system, which is based on Java. MapReduce breaks down a large data processing operation into smaller tasks, making it easier to handle. This is also in charge of processing large datasets simultaneously before reducing them to obtain the desired result. Hadoop MapReduce is a Hadoop framework built on the YARN architecture. Furthermore, the Hadoop design based on YARN allows for distributed parallelization of large data volumes. And MapReduce provides a foundation for writing applications that can run on thousands of servers with ease. It also considers the flaw, and failure management is used to reduce risk.
The operation of MapReduce is based on a fundamental processing principle. The “Map” job, in other words, delivers a query to different nodes in a Hadoop cluster for processing. And the “Reduce” operation compiles all of the results into a single value.
Nodes with workers
Most of the distributed computing virtual servers (VM) in a Hadoop are located on these nodes. They are responsible for data storage and calculations across clusters. In addition, each worker node hosts the DataNode & TaskTracker services. They’re useful for retrieving instructions from controller nodes for processing.
Nodes that serve as clients
The participating nodes are in charge of loading data into the cluster. These nodes start by submitting MapReduce tasks that specify how data should be processed. When the processing is finished, they retrieve the results.
Hadoop Components

Image Source: Link
The fact that numerous Hadoop modules provide excellent support for the system.
HDFS
Within Big Data, the Hadoop Distributed File System, or HDFS, aids in the storage and retrieval of many files at rapid speeds. The GFS article, issued by Google Inc., served as the foundation for HDFS. This specifies that the files would be divided into blocks & stored in the distributed structure’s nodes.
Yarn
YARN, or Yet Another Resources Negotiator, is a handy tool for work planning and cluster management. It aids in improving the system’s data processing efficiency.
Reduce the size of the map

Image Source: Link
As previously said, Data Compression is a model that provides a Java program. It’s a framework that allows Java programs to handle data in parallel using key-value pairs. The Map job takes incoming data and transforms it into a set of data that can be used to compute the Key value combination. The Reduce task takes the output of the Map job, and then the reducer’s output generates the desired result.
Hadoop Basics
These are Java libraries used to get Hadoop up and running and other modules. It’s a collection of tools that support Hadoop’s numerous modules.
Exploring Hadoop’s Data Processing Model
Hadoop’s data processing model is incredibly powerful and can help with analyzing large pools of structured, semi-structured, or unstructured data. It consists of four core components – MapReduce, HDFS (Hadoop Distributed File System), YARN (Yet Another Resource Negotiator), and Common. Each component has its own unique purpose in the Hadoop processing pipeline. The MapReduce framework processes a data set through multiple mappers that apply various filters to subset datasets for each given query. These subsets are then distributed amongst nodes which combine them into one master copy which is referred to as the reducer.
HDFS serves to manage the underlying disks hosting Big Data sets for both read/write transactions around these datasets and data synchronization from remote locations if needed. YARN does compatibility checks when it comes to combining different resources on multiple machines within a cluster environment, like client nodes requesting specific tasks at any given time across this distributed architecture. Finally, Common provides an API library that integrates existing applications inside Apache Hadoop, such as Hive or Pig Scripting Languages, while also providing support services, including authentication protocols, security logging frameworks, etc.
Scalability and Fault Tolerance in Hadoop Distributed Computing
Scalability and fault tolerance are key aspects of its strong functionality. With the large-scale use of Hadoop in many organizations, it is necessary for it to be able to scale easily and robustly with high availability levels and no single point of failure. This ensures that if one node fails, another automatically takes over. The distributed nature of computing provides stability by allowing jobs to quickly recover from a node going down or a disk failing unexpectedly.
Additionally, multiple instances can run simultaneously on the same cluster resulting in improved performance when running more complex analytical processes, along with cost savings due to optimization through parallel processing capabilities. When you scale up cheaper hardware into larger clusters, you can significantly improve compute time latency, often without requiring additional investment in expensive machines and infrastructure. This approach also ensures fault tolerance by replicating data across multiple systems, preventing a full system failure and the permanent loss of valuable data in the event of an unexpected outage.
Hadoop’s Data Replication and Data Locality Concepts
Hadoop has revolutionized data storage and analysis with its data replication and data locality concepts. Data replication backs up information and ensures its accessibility by replicating it across multiple machines in a cluster. Conversely, data locality enhances the performance of Hadoop applications by storing data in the physical location where it is most frequently used, thereby conserving resources and speeding up processing times. This helps reduce network latency when accessing large datasets from different locations around the world. By combining these two concepts, organizations are able to increase their ability to quickly analyze large datasets while ensuring that their sensitive or personal information remains secure.
Distributed Data Storage and Retrieval in Hadoop
Hadoop is emerging as the next big step in large-scale data storage and retrieval because it actively distributes data storage and retrieval. In a nutshell, distributed data storage involves taking large, disparate chunks of data stored on different locations and systems–and often across multiple IT infrastructures–and combining them into one cohesive unit with a single point of access. This allows for efficient utilization of hardware resources while simultaneously allowing users to retrieve the needed data from anywhere within the organization. Demand for this form of technology is growing rapidly, and you can see that put to use in everything from banks keeping track of customer records to airlines managing flight livery details.
Each industry has unique needs when it comes to storing its vast amounts of information, but they all benefit from Hadoop’s ability to provide scalable distributed computing capabilities which are both flexible and cost-effective. With proper implementation, organizations can quickly integrate their existing systems with new technologies such as NoSQL databases or Big Data solutions, allowing them greater control over their data stores while freeing up valuable time spent manually managing outdated legacy systems.
Performance Optimization Techniques for Hadoop Distributed Computing
The advent of Hadoop distributed computing has revolutionized the way you perform big data analytics. The massive scalability, fault-tolerance and easy access to compute resources make Hadoop an invaluable platform for today’s businesses. However, to fully take advantage of this incredible technology, employing performance optimization techniques is vital. By taking the time to understand how this powerful system works and by optimizing your clusters accordingly you can increase efficiency while decreasing costs.
The team at Skynet Technologies Inc have come up with a list of our top tips for boosting productivity when using Hadoop:
1) Make sure hardware meets specifications – Check soon after deployment that all nodes within a cluster have good hardware specs and enough RAM, storage capacity and network bandwidth required as per application needs;
2) Install appropriate tools such as Oozie or Azkaban to deploy proper workload management policies, ensuring you assign tasks properly depending on their resource intensity.
3) Use job scheduling algorithms – Leverage pre-built algorithms like FIFO, LIFO or SKIP/NEXT to optimize scheduling according to best fit available resources;
Security Considerations in Hadoop Distributed Computing
Security considerations in Hadoop distributed computing are some of the most important topics to consider when utilizing Hadoop in any environment. When dealing with sensitive information, organizations must properly secure and protect their systems from malicious attacks or unauthorized access. It is essential to understand the security architecture of a Hadoop cluster, as well as best practice policies for data encryption and authentication.
It is also important to note that authorization processes need to exist within the framework since there may be different levels for users who have access to certain parts or resources of a distributed system. Finally, all communications between machines should be secure (e.g., using SSH tunneling). Additionally, you must implement security measures to safeguard the data replication process in HDFS and ensure that accidental failures on majority nodes do not cause the loss of valuable client data. This is crucial, especially when these failures occur over time across clusters distributed geographically across multiple locations.