What’s Distributed Computing and How Does It Work?
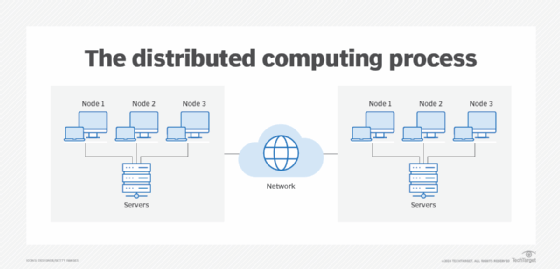
Image Source: Link
The practice of connecting numerous computer servers via a network into a cluster to share data and coordinate processing capacity is known as cloud applications (or distributed processing). A “distributed system” is the name given to such a cluster. Scalability (through a “scale-out design”), performance (via parallelism), robustness (by redundancy), and cost-effectiveness are all advantages of distributed computing.
Cloud technology has become highly widespread in application and database design as data volumes have ballooned and application performance expectations have risen. This is why scaling is important because as data volumes expand, the extra burden can be managed by adding more equipment to a system.
In contrast, typical “big iron” setups made mainly of good computer servers must deal with load growth by upgrading & replacing hardware.
Cloud Computing Distributed Computing

Image Source: Link
Distributed computing has become even more accessible because of the proliferation of cloud computing choices and suppliers. While cloud computing instances do not inherently enable cloud applications, numerous forms of distributed software may be run in the cloud to take full advantage of the available computing resources.
To be able to share, organizations formerly relied upon (DBAs) or technology providers to link computational power across the networks within and beyond data centers. Leading cloud companies are now making it easier to add computers to the cluster for increased storage capacity or performance.
Distributed computing allows for better agility when dealing with expanding workloads due to the ease and speed with which additional computing resources may be deployed. This allows for “elasticity,” where a cluster of machines may readily expand or contract in response to changing workload demands.
Key Benefits

Image Source: Link
Distributed computing allows all of the computers in a cluster to function as if they were one. While this multi-computer architecture has some complexity, it also has several significant advantages:
Performance. Through a divide-and-conquer technique, the cluster can reach high-performance levels by using parallelism, in which each device handles a portion of an overall task simultaneously.
Resilience. To ensure no point of failure, distributed computing clusters often copy or “replicate” data across all data centers. If a computer fails, copies of its data are kept elsewhere to ensure no information is lost.
Cost-effectiveness. Distributed computing often uses low-cost commodity hardware, making both initial deployments and cluster expansions relatively cost-effective.
Scalability. Scaling distributed computing clusters is simple thanks to a “scale-out architecture,” allowing bigger loads to be managed by simply adding more hardware.
Why would you want to spread a system?

Image Source: Link
By necessity, systems are constantly scattered. The truth is that operating systems are a difficult topic fraught with pitfalls and landmines. Deploying, maintaining, and debugging distributed systems is a pain, so why bother?
Scaling horizontally is possible with a distributed system. Returning to our single database server example, the only method to manage increased traffic is to improve the system’s hardware. You can refer them to as vertical scaling.
After a certain level, it is substantially less expensive than vertical scaling. However, this is not the primary reason for the choice.
Scalability can only bring your efficiency up to par with the latest gear. For technology enterprises with moderate to large workloads, these capabilities are insufficient.
The nicest part of scalability is that there is no limit to what you can grow — if performance decreases, add more machines, potentially indefinitely.
The ability to scale easily isn’t the only advantage of distributed systems. Fault tolerance and reduced latency are other essential considerations.
Fault Tolerance –
A cluster of 10 machines spread across two data centers is more fault-tolerant than a single system. Your application would continue to function even if one of the data centers caught fire.
Low Latency –
The light speed physically limits the time it takes for a data link to travel across the planet. For example, in an optic fiber connecting New York and Sydney, the shortest time shaped time (the time it takes for a request to travel back and forth) is 160ms. With distributed systems, you can have a node in each city, allowing traffic to the closest node.
However, developers must specifically design the program to operate effectively on multiple devices simultaneously and address the associated challenges for a dispersed system to function effectively. This proves to be a difficult task. Vertical scaling is great while it lasts, and after a certain point, even the best technology will be insufficient to handle sufficient traffic, not to say prohibitive to the host.
Installing more machines rather than increasing the architecture of a single machine is what horizontal scaling entails. Some important points are mentioned underneath:
- Distributed Systems are difficult to understand.
- You can choose them because of scale and cost considerations.
- They are more difficult to work with.
- The CAP Theorem entails a trade-off between consistency and availability.
Challenges and Limitations of Distributed Computing
Distributed computing has many advantages, but it also comes with a unique set of challenges and limitations. One of the greatest challenges is mitigating the potential security risks involved in transmitting data to different locations over a network. Hackers often target distributed systems because they can access more sensitive data than if they just targeted a single system or server. Without proper precautions, data gathered from multiple locations can be vulnerable to cyber attacks that could compromise the integrity of the system as well as any confidential information stored within it. Another major limitation involves latency issues when sending or receiving large amounts of data across long distances; this can cause delays in real-time communication or applications that require immediate responses.
Additionally, since distributed systems rely on multiple components to function properly, maintenance and repair costs are often higher than for traditional computers due to regular upgrades and support services needed at each site. Lastly, some individuals may have difficulty adapting to an unfamiliar software interface offered by a hosted solution which could lead to increased user training requirements if not managed correctly. In spite of these obstacles though, distributed computing offers numerous benefits including scalability and reliability which makes it an attractive option for businesses ranging from small startups to large enterprises looking for ways maximize efficiency through cloud solutions.
Distributed Computing Models: Centralized vs. Decentralized
Distributed computing models span multiple physical systems and differ in their approaches to data sharing and processing. Centralized distributed computing models process data on one single machine, while decentralized ones distribute it over a number of devices. The centralized model operates more efficiently in smaller operations, as it requires fewer resources. In contrast, the decentralized model scales more effectively with large datasets, distributing processing across individual machines to prevent overburdening a single machine with all the task load.
Moreover, this approach enhances security by eliminating any possible single point of failure or attack target. Finally, both approaches have their pros and cons when it comes to fault tolerance and latency issues. Ultimately you will need to decide which method best suits your needs based on the speed trade-offs versus risk mitigation requirements for your specific application environment.
Components and Architecture of Distributed Computing System
In distributed computing, the components and architecture of the system are separate from each other but depend on each other for communication. The main components in a distributed computing system include clients, servers, database systems, web or application servers, and storage elements. Clients typically run applications that enable users to connect to their networks and access services located on remote sites across the world wide web (WWW). Servers provide services such as authentication; file sharing data management; processing requests from clients; providing network resources such as printing services; e-mail forwarding; managing databases etc.
Database systems provide storage support and data backup, while application servers allow dynamic content generation for applications delivered over HTTP. Storage elements contain disks where you can store large amounts of data securely. In addition to these components, a distributed computing system has several layers, including the hardware platform layer, software architecture layer, and application service layer. Each layer is responsible for specific tasks depending upon its purpose within the overall architecture.
Communication and Coordination in Distributed Computing
In a distributed computing environment, communication and coordination between the different components of the system are essential for efficient execution. Message passing enables communication by facilitating the transmission of data between computers over a network. Coordination establishes a common understanding among nodes, helping them reach agreement on upcoming tasks and their respective responsibilities.
Additionally, it is important to ensure that no node in the system becomes overloaded with work or stranded without resources due to poor load balancing or insufficient fault tolerance mechanisms. To meet these challenges, distributed systems often employ sophisticated techniques such as deadlock detection, load balancing algorithms, replication strategies, and resource allocation protocols. By leveraging these methods of communication and coordination in distributed computing environments, organizations can realize significantly improved performance while maintaining reliability at scale.
Scalability and Performance in Distributed Computing
Scalability and performance in distributed computing is an important topic in computer science, as many of today’s modern enterprise applications require distributed computing in order to be efficient and effective. By understanding the principles of scalability and performance, organizations can design their systems so that they are more reliable and capable of meeting demanding use cases. Designing algorithms for distributed systems, utilizing scalable databases or frameworks with solid optimization techniques, adjusting scale according to fluctuating workloads as necessary, and prioritizing security while delivering services across networks all fall under this category.
Additionally, IT professionals must also understand how cloud-based solutions work together with disaggregated architectures to deliver high availability while ensuring a secure environment for users’ data. By leveraging the concept behind distributed computing capabilities such as microservices and containers, organizations can easily scale up their resources on demand when needed without having to worry about complex implementations.
Fault Tolerance and Reliability in Distributed Computing
SystemsReliability and fault tolerance are two very important factors when it comes to distributed computing systems. Fault tolerance is the ability of a system to continue functioning normally even if there is an error or unplanned event occurring with some part of a component in the system. It is essential that any distributed computing system must have redundancy, both at hardware and software levels, so as to ensure its continued operation despite such errors.
Redundancy minimizes downtime due to single node failure by providing backup nodes that can take over for failed components. Additionally, data integrity, a component of reliability, ensures that the architecture of the distributed computing system processes all transactions without losing or tampering with them.
High availability and scalability also provide extremely valuable features for any reliable distributed computer infrastructure, guaranteeing uninterrupted operation during peak resource loads and efficient operation of large-scale applications without crashes over time. Lastly, security plays an important role in maintaining reliability by preventing unauthorized access, which could impact performance or corrupt sensitive information within a networked environment.