What exactly is GPFS?
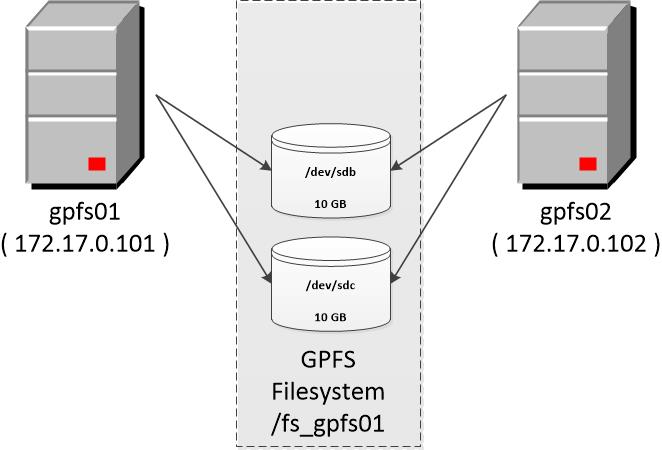
IBM Spectrum Scale, formerly known as the General Parallel File System (GPFS), is a high-performance clustered file system software that IBM evolved in 1998. It was initially intended to support high-streaming media as well as entertainment applications. It can be used in shared-disk, shared-nothing, or a correlation between the two distributed parallel mechanisms. The most common deployment is a shared-disk solution, with SAN block storage used for persistent storage.
Data accessibility
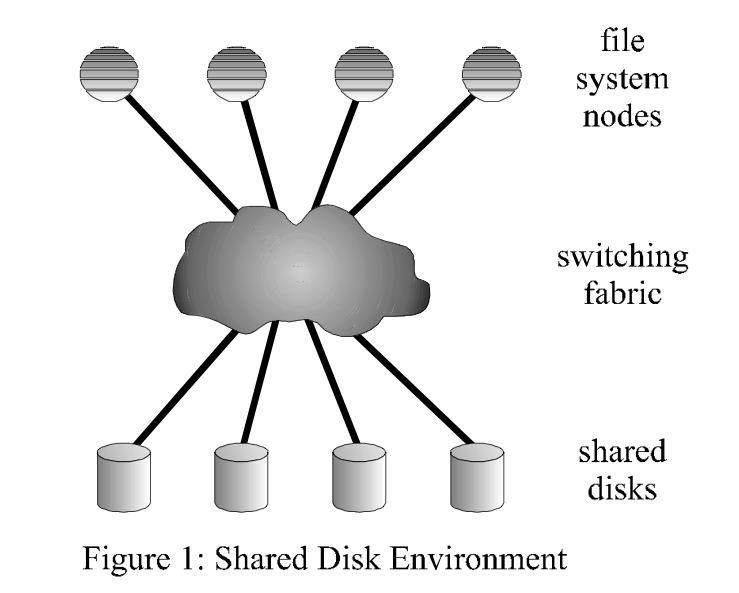
GPFS is fault-tolerant and can be configured to allow data access even if cluster nodes or storage systems fail. This is achieved through robust clustering features and data replication assistance.
GPFS continually monitors the file system components’ health. When failures are detected, the appropriate recovery action is automatically taken. Extensive logging and recovery capabilities are provided when application nodes holding locks or performing services fail to maintain metadata consistency. Journal logs, metadata, and data can all be replicated. Replication enables continuous operation even if a disc path or the disc itself fails.
Combining these features with a high-availability infrastructure ensures a dependable enterprise storage solution.
Locking and distributed management in GPFS

Like many others, the GPFS distributed lock manager employs a centralized global lock manager operating on one of the cluster nodes in collaboration with the local locks managers in every file system node. The lock manager syncs lock amongst the local lock managers by circulating lock tokens, showing the right to grant dispersed locks without requiring a separate communication protocol each time a lock is procured or launched. Repeated accesses from the same node to the same disc object require only a single message to obtain the right to purchase a lock on the object (the lock token).
After a node obtains the token from the worldwide lock manager (also known as the token manager or token server), subsequent operations issued by the same node can obtain a lock on the same object without additional messages. Only when a procedure on some other node necessitates the revocation of a conflicting lock on the same object are supplemental messages required to revoke the lock token from the first node and grant it to the other node. Lock tokens are also used to maintain cache consistency between nodes. A token enables a node to cache data interpreted from a disc because the data cannot be altered elsewhere unless the token is first revoked.
- GPFS supports flock () from multiple nodes on the same file parallel. You can also use maxFcntlRangePerFile to clarify the total amount of fcntl() locks per file.
- It supports byte scope locking, so the entire file is not barricaded. • Distributed management
- Customers share data and metadata utilizing POSIX semantics.
- Sharing and synchronization are managed by distributed locking, allowing byte ranges.
- The management interface is the GPFS daemon on every node.
- The file manager controls token metadata management.
- Nodes need tokens for reading/writing operations.
- The token supervisor coordinates requests, which include conflict resolution.
Keeping parallelism and consistency in check
![PDF] File Systems and Storage on Making Gpfs Truly General the Basics Where He Serves as a Technical Leader of the Parallel File Systems Group and Principal Architect of Ibm's General Parallel](https://d3i71xaburhd42.cloudfront.net/84ff5931051ff905b313669415e10e068d1c9ee9/2-Figure1-1.png)
There are two options. The first is distributed locking, which involves consulting all other nodes, and the second is centralized management, which involves consulting a single node. GPFS is a hybrid solution. Every node has a local lock manager, and a global lock manager manages them by handing out tokens/locks.
To create a synchronization between Read and Write for filing data, GPFS employs byte-range locking/tokens. This enables parallel applications to write simultaneously to different parts of the same file. (If the end-user is the writer, it will obtain a lock on the entire file for efficiency reasons.) Only when other clients are interested do we use finer granularity locks.)
Access to metadata must be synchronized.
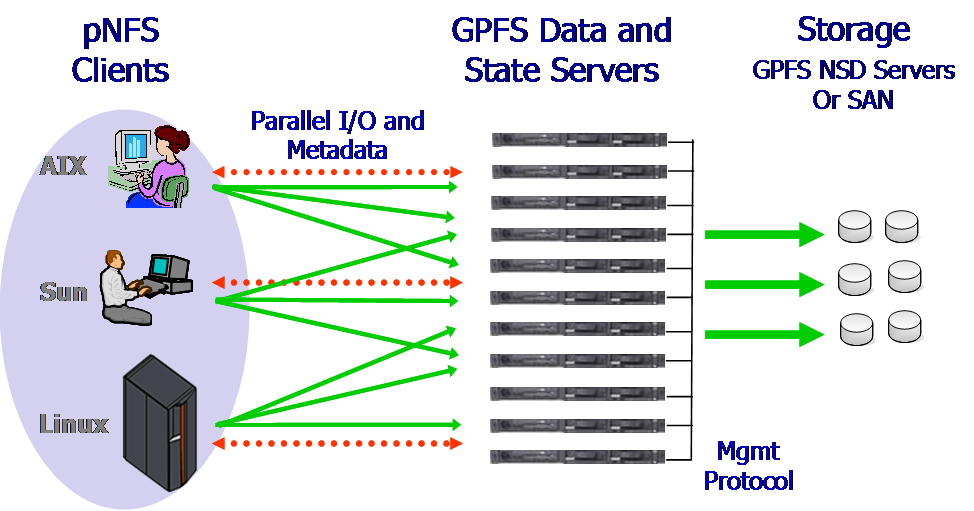
There isn’t a centralized metadata server. Each node stores metadata for the files over which it has authority and is known as the metadata coordinator (metanode). The metanode for a file is dynamically selected (the paper does not go into detail), and only the metanode reads and writes the inode for the file from/to disc. The metanode syncs access to the files’ metadata by offering other nodes a shared-write lock.
Fault-tolerance
When a node fails, GPFS restores any metadata updated by the failed node, releases any tokens held by the failed node, and appoints replacements for this node for metanode allocation manager roles. Because GPFS stores log on shared discs, any node can perform log recovery on the failed node’s behalf.
Information Management
The storage helps in pooling several disks in the file system. The administrator can make storage tiers by grouping the disks based on performance, reliability characters, and localities. For instance, a single pool can give you a high-performance channel of fiber disks and less expensive SATA storage.
FAQs
What is GPFS distributed file storage, and how does it differ from traditional file systems?
GPFS distributed file storage is a high-performance, shared-disk file system designed for parallel computing environments. Unlike traditional file systems that are typically limited to a single server, GPFS allows multiple servers to access the same storage simultaneously, enabling scalable and high-throughput data access for demanding workloads.
What are the advantages of using GPFS distributed file storage?
The advantages of GPFS distributed file storage include:
-
- Scalability: Easily scales to accommodate growing data volumes and increasing computational demands.
- High performance: Provides parallel access to data, enabling high throughput and low latency for data-intensive applications.
- Shared access: Allows multiple servers to access the same storage simultaneously, facilitating collaboration and resource sharing.
- Fault tolerance: Implements redundancy and fault-tolerant mechanisms to ensure data availability and reliability in the event of failures.
How does GPFS distributed file storage handle data access and storage?
GPFS distributes data across multiple storage devices and servers, allowing parallel access to data blocks. Data access is coordinated by GPFS metadata servers (MMs), which manage file system metadata and coordinate access to files. Data servers (NSDs) store and serve data blocks to clients, providing scalable and efficient data storage.
Is GPFS distributed file storage suitable for my workload?
GPFS distributed file storage is well-suited for a wide range of workloads, including scientific research, engineering simulations, big data analytics, and AI/machine learning applications. If your workload requires high throughput, low latency data access, scalability, and shared access to data among multiple servers, GPFS may be an ideal solution.
Can GPFS distributed file storage be deployed on-premises or in the cloud?
Yes, GPFS distributed file storage can be deployed both on-premises and in the cloud. On-premises deployments typically involve dedicated hardware infrastructure, while cloud deployments leverage cloud storage services such as IBM Cloud Storage or Amazon S3. GPFS offers flexibility and interoperability, allowing seamless integration with various storage environments.
What are the key considerations for deploying GPFS distributed file storage?
Key considerations for deploying GPFS distributed file storage include:
-
- Hardware requirements: Ensure that your hardware infrastructure meets the performance and scalability requirements of GPFS.
- Network configuration: Optimize network connectivity to minimize latency and maximize throughput between GPFS nodes.
- Workload analysis: Assess your workload characteristics and performance requirements to determine the optimal GPFS configuration.
- Data protection: Implement data redundancy and fault-tolerant mechanisms to ensure data availability and reliability.
How can I get started with GPFS distributed file storage?
Getting started with GPFS distributed file storage involves:
-
- Consulting with GPFS experts or vendors to assess your storage needs and design an optimal deployment architecture.
- Acquiring the necessary hardware and software components for GPFS deployment.
- Deploying and configuring GPFS according to best practices and recommended guidelines.
- Testing and optimizing the GPFS deployment for your specific workload requirements.
- Implementing monitoring and maintenance procedures to ensure ongoing performance and reliability.