

Machine learning is one of the hottest topics in technology today. But why do we need machine learning? What is machine learning, and how is it related to sci-fi’s favorite term, Artificial intelligence? Let’s take a look.
Machine learning is a rapidly evolving field within the broader domain of artificial intelligence (AI). It encompasses a set of algorithms and techniques that enable computers to learn and improve from experience without being explicitly programmed. In other words, machine learning algorithms have the ability to automatically analyze and extract patterns from data, and use these patterns to make predictions or take actions.
Need for Machine Learning
The term Machine Learning was coined by Arthur Samuel (1959), an American pioneer in the field of computer gaming and artificial intelligence, and stated that “it gives computers the ability to learn without being explicitly programmed.”
Since the internet became popular, the amount of data generated worldwide has been immeasurable. According to Forbes, Americans use 4,416,720 GB of internet data, including 188,000,000 emails, 18,100,000 texts, and 4,497,420 Google searches every minute.
With so much data available and computational processing getting cheaper and much more powerful, something had to be done with this data. That’s when machine learning was born, and it became a way for humans to understand critical aspects of the vast amount of data.
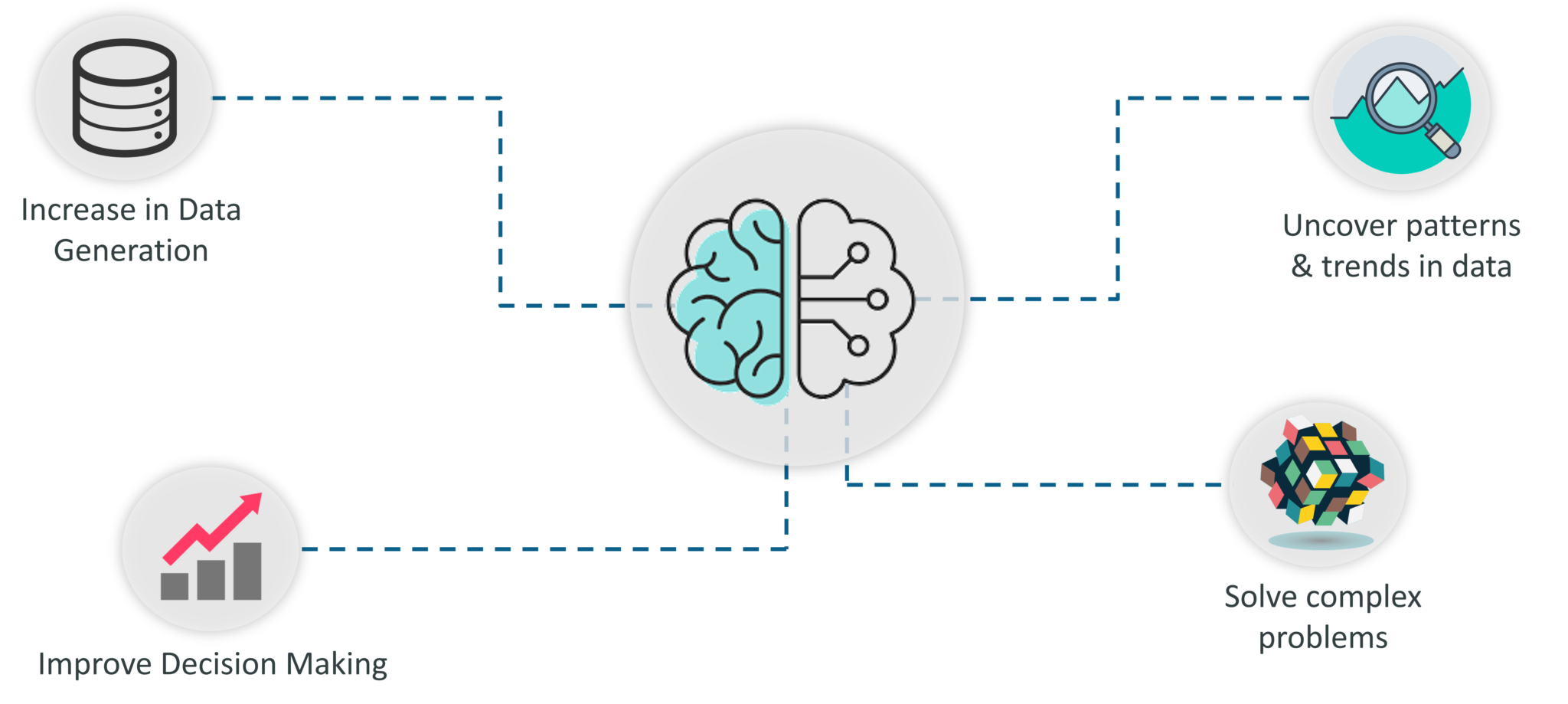
Most top-tier companies build machine learning models to identify profitable opportunities and avoid risks.
These machine learning models improve decision-making by doing tasks such as predicting whether a stock will go up or down, forecasting company sales, etc. They also help uncover patterns and trends in datasets and solve super-complex problems.
Artificial Intelligence and Machine Learning
Artificial intelligence (AI) is a simulation of human intelligence in machines in a way that machines imitate human actions or have the ability to learn and solve problems. Some popular use cases of AI are Siri, Alexa, and Self-driving cars.
Machine Learning (ML) is a subset of AI which allows machines to learn from past data without being programmed explicitly. Tasks such as making predictions and classifying things into categories are a part of ML. Some examples of ML that are seen all around us are:
Netflix’s Recommendation System: Netflix uses a dataset of users who watched similar movies and other factors like genre, actors, etc., to figure out which movies to recommend.
Facebook auto friend tagging: Facebook uses Machine learning and Neural networks to perform facial recognition to recognize who is who.
Google’s spam filter: Google uses Machine learning and Natural language processing to check emails and classify emails as spam or not.
ML is also used in self-driving cars, cyber fraud detection, customer support chatbots, etc.
How does Machine Learning work?
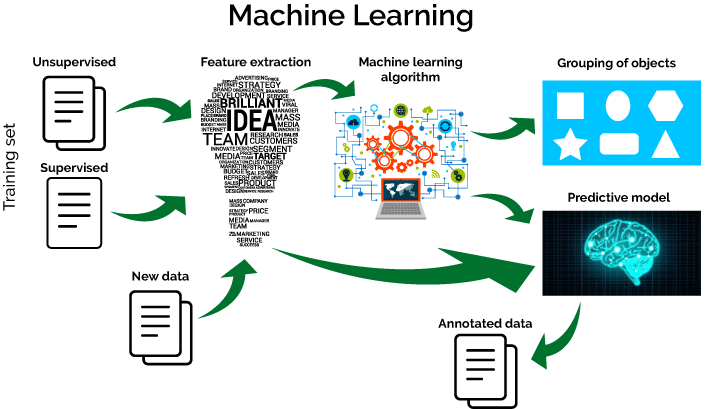
A machine learning model takes historical data and uses it to make predictions.
Some terms that should be known before moving forward.
Algorithm:
A set of rules and techniques to understand the pattern and get information from the dataset. This is the logic part of the machine learning model.
Model:
The main component in machine learning is trained by using the algorithm. The model takes an input, runs the algorithm based on it, and produces an output.
Training dataset: This is the dataset that helps identify the trends and patterns and is used to predict the needed output.
Testing dataset: After the model is trained and the model’s accuracy is evaluated using the testing dataset.
Now using these terms:
Historical data, also referred to as training datasets, our machine learning algorithms build a mathematical model that makes predictions without being conventionally programmed. These models are a practical application of statistics.
The model’s performance will increase as more information is provided.
Block diagram on working of a Machine learning algorithm
(Source: https://www.javatpoint.com/machine-learning)
When working with datasets on a machine learning model, the following are some broad steps that can be followed:
Step 1 Importing Data
There are 4 major types in which data will be available for use, i.e., CSV, JSON, SQLite, and BigQuery.
The following code can be used when working with .csv files in Python.
| import pandas as pd df = pd.read_csv (r’Path where the CSV file is stored\File name.csv’) |
Step 2 Data Preprocessing
Depending on the dataset, this may vary. The cleaning of some datasets may be minimal, such as adding NULL values to missing entries, but some datasets may require a lot of effort.
A good understanding of the data is required for this step. Graphs and charts can help us better understand the data so that we can recognize trends at a glance. Plotly, Matplotlib, or Seaborn are examples of Python libraries suitable for this purpose.
Step 3 Split the Data into Training/ Testing sets
Train-test splits are a way to evaluate the performance of machine learning algorithms. The procedure involves dividing a dataset into two subsets.
Here is a sample code of how you can achieve using Sklearn:
| from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df, y, test_size=0.2) |
Here the dataset, df, gets split into an 80/20 ratio ( as shown by the 0.2 value at the end of the code). Here, X is the independent variable, and y is the dependent.
To avoid overfitting or underfitting, cross-validation methods are used, such as K-Folds Cross-Validation and Leave One Out Cross-Validation.
Step 4 Creating a model.
Now, you can use the data that is now ready with a machine-learning model. Moreover, you can use regression, classification, clustering, or deep learning algorithms \depending on the dataset.
A detailed discussion of this step will be covered in future lessons.
Step 5 Training a model
You can use training data in this step to try and achieve the desired result. It changes the weights and biases after checking the result (an ideal model would have no loss). Thus, training a model aims to find weights and biases that, on average, have low loss across all examples.
You can call this process empirical risk minimization.
Step 6 Make Predictions
After the model is trained, it provides a prediction. The word prediction is a little misleading because only in the time series algorithm is the future predicted. The other algorithms might classify the data or determine the estimate of a dependent variable.
Step 7 Evaluate and Improve
Now, we send the testing dataset to the model and test its accuracy. The higher the accuracy, the better the algorithm has been trained. Various testing methods, such as the F1 test, create a confusion matrix or ROC curve.
Once all this information is available, we repeat whichever above step is necessary to make our model closer to the desired outcome.
Note- No Machine learning model will provide 100% accuracy; if it does, it might be a case of overfitting.
The Rise of Machine Learning
Machine learning has gained immense popularity and significance in recent years due to several factors. First, the exponential growth of data has made it increasingly challenging for humans to manually analyze and extract meaningful insights from vast datasets. Machine learning algorithms, on the other hand, are capable of efficiently processing and extracting patterns from large volumes of data, enabling organizations to derive valuable insights and make data-driven decisions.
Second, advancements in computing power and storage capabilities have facilitated the application of complex machine learning algorithms to real-world problems. Thanks to the availability of powerful hardware and distributed computing systems, you can now train machine learning models on massive datasets within a reasonable timeframe.
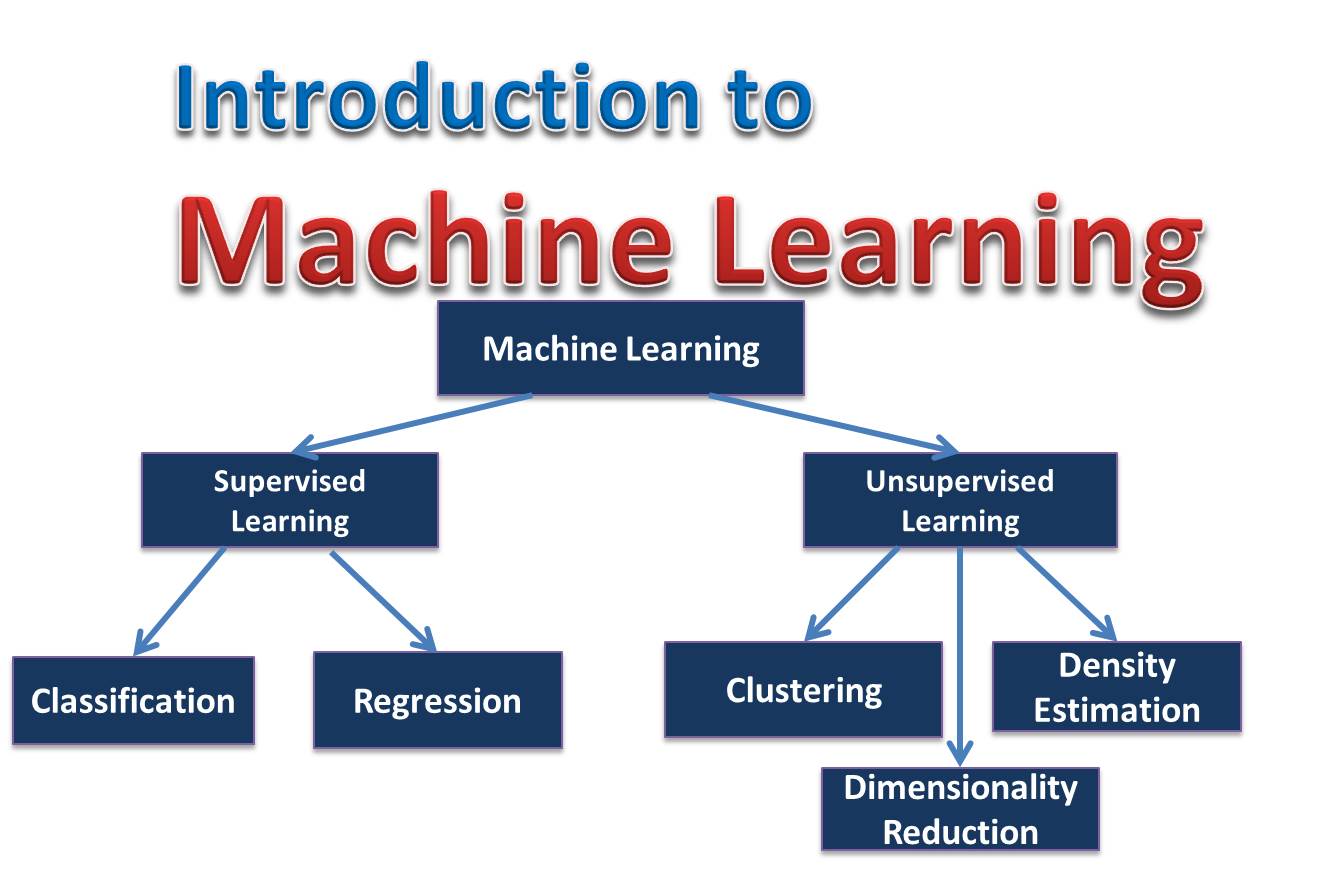
Types of Machine Learning
You can broadly classify machine learning techniques into three main types:
- Supervised Learning: Supervised learning is the most common and widely used type of machine learning. It involves training a model on a labeled dataset, where the input data (features) is accompanied by corresponding output labels. The goal of supervised learning is to learn a mapping function that can predict the output labels for new, unseen data accurately. The training process involves iteratively adjusting the model’s parameters to minimize the difference between the predicted and actual labels.
You can further categorize supervised learning into two subtypes: classification and regression. Classification tasks involve predicting discrete class labels, while regression tasks involve predicting continuous numerical values.
- Unsupervised Learning: Unsupervised learning, as the name suggests, involves learning from unlabeled data. In this type of machine learning, the algorithm explores the data and identifies underlying patterns or structures without any prior knowledge of the output labels. Unsupervised learning algorithms aim to discover hidden relationships and groupings within the data.
Clustering and dimensionality reduction are common techniques that you can use in unsupervised learning. Clustering algorithms group similar data points together based on their inherent similarities, while dimensionality reduction techniques reduce the number of input features while preserving important information.
- Reinforcement Learning: Reinforcement learning involves training an agent to make sequential decisions based on interactions with an environment. The agent receives feedback in the form of rewards or penalties based on its actions. Through trial and error, the agent learns to take actions that maximize the cumulative reward over time. You can use reinforcement learning in tasks that require decision-making in dynamic and uncertain environments.
Key Steps in Machine Learning
The process of building a machine learning model typically involves several key steps:
- Data Collection: Gathering and preparing a suitable dataset is crucial for machine learning. The dataset should accurately represent the problem domain and contain relevant features and labels.
- Data Preprocessing: Data preprocessing involves cleaning the dataset by handling missing values, removing outliers, and normalizing or scaling the features. It ensures that the data is in a suitable format for training the machine learning model.
- Model Selection: Choosing an appropriate machine learning model depends on the problem at hand, the available data, and the desired outcome. Different algorithms and models have different strengths and limitations, and selecting the right one is essential for achieving accurate predictions.
- Training the Model: Training the model involves feeding the labeled training data to the algorithm and optimizing its parameters to minimize the difference between predicted and actual values. This process typically involves an iterative approach, adjusting the model’s parameters until it reaches a satisfactory level of accuracy.
- Model Evaluation: Evaluating the performance of the trained model is crucial to assess its accuracy and generalization capability. This involves testing the model on a separate set of data (the test set) and measuring various metrics such as accuracy, precision, recall, and F1-score.
- After training and evaluating the model, the next step is model deployment. This involves integrating the model into the target system or application, allowing it to make predictions on new, unseen data and provide real-time decision-making capabilities.
Applications of Machine Learning
Machine learning has found applications in a wide range of fields and industries. Some notable applications include:
- Image and speech recognition
- Natural language processing
- Recommendation systems
- Fraud detection
- Financial forecasting
- Healthcare diagnostics
- Autonomous vehicles
- Predictive maintenance
Conclusion
Machine learning is a transformative field that enables computers to learn and make predictions based on data. With the ability to automatically extract patterns and insights from large datasets, machine learning has the potential to revolutionize numerous industries and domains. By understanding the different types of machine learning and the key steps involved in building a model, organizations can harness the power of data to gain valuable insights and make informed decisions.
FAQs
What is machine learning?
Machine learning is a subset of artificial intelligence (AI) that focuses on enabling computers to learn from data without being explicitly programmed. Instead of relying on predefined rules, machine learning algorithms learn patterns and relationships from the data and use that knowledge to make predictions or decisions.
How does machine learning work?
In machine learning, algorithms are trained on a dataset to learn patterns or representations that exist within it. This training process involves adjusting the parameters of the model to minimize errors or discrepancies between predicted outcomes and actual data. Once trained, the model can generalize its learning to new, unseen data, making predictions or taking actions based on its learned knowledge.
What are the types of machine learning?
Machine learning can be broadly categorized into three types: supervised learning, unsupervised learning, and reinforcement learning. Supervised learning involves learning from labeled data, where the algorithm is trained on input-output pairs. Unsupervised learning, on the other hand, deals with unlabeled data, aiming to uncover hidden patterns or structures within it. Reinforcement learning focuses on training agents to make sequential decisions by interacting with an environment and receiving feedback in the form of rewards or penalties.
What is supervised learning?
Supervised learning is a type of machine learning where the algorithm learns from labeled data, consisting of input features and corresponding output labels. The goal is to learn a mapping function that can predict the output labels for new, unseen input data accurately. Common tasks in supervised learning include classification, where the output is a category or label, and regression, where the output is a continuous value.
What is unsupervised learning?
Unsupervised learning involves training machine learning algorithms on unlabeled data, where there are no predefined output labels. Instead, the algorithm aims to find hidden patterns, structures, or relationships within the data. Clustering and dimensionality reduction are common tasks in unsupervised learning, where the goal is to group similar data points or reduce the complexity of the data while preserving its essential characteristics.
What is reinforcement learning?
Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with an environment. The agent takes action and receives feedback from the environment in the form of rewards or penalties, which it uses to learn optimal strategies or policies to achieve its goals. Commonly, you can use Reinforcement learning in applications such as game playing, robotics, and autonomous vehicle control.
What are the applications of machine learning?
Machine learning finds applications across various domains, including but not limited to image recognition, natural language processing, recommendation systems, finance, healthcare, and autonomous vehicles. You can use it to automate tasks, make predictions, extract insights from data, and improve decision-making processes in a wide range of industries and sectors.



