Fault tolerance is an idea used in many fields, but it’s far especially essential to data storage and facts technology infrastructure. Fault-tolerance refers to the ability of a laptop device or garage subsystem to go through failures in factor hardware or software parts yet retain function without a provider interruption – and without dropping facts or compromising protection.
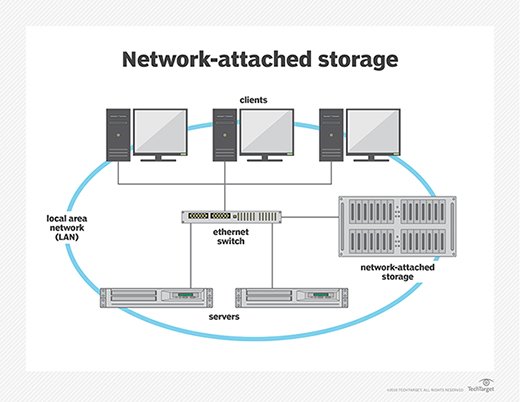
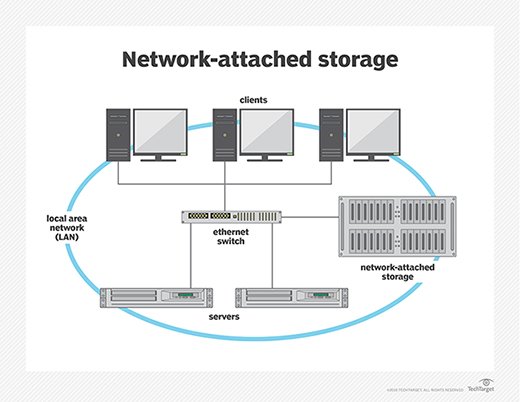
Fault tolerance in structures can embody a whole lot of the statistics garage platform, from SSD to HDD to RAID to NAS. A NAS device is a garage tool that links to a community that allows storage and retrieval of facts from a significant location for network users and different clients. NAS devices are flexible and scale-out, meaning that as you want additional storage, you may upload to what you have. NAS reliability is like having a non-public cloud within the office. It’s faster, much less pricey, and offers all the benefits of a public cloud on a website, giving you complete management.
NAS reliability systems are perfect for SMBS.
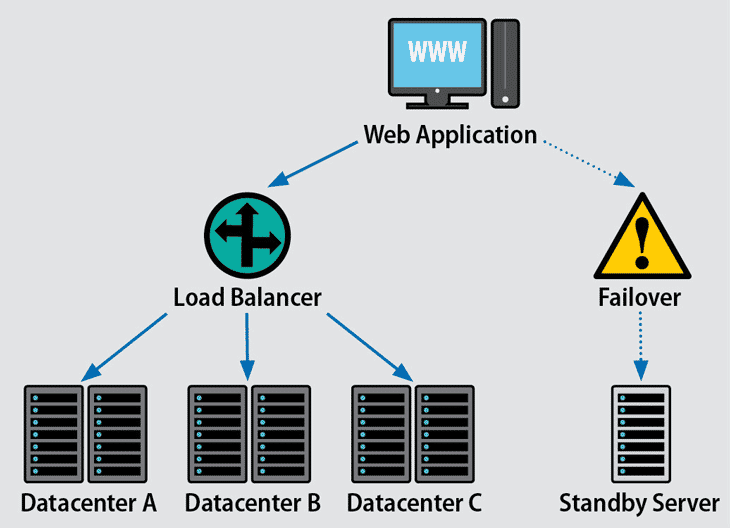
Image Source: Link
- Simple to perform, a devoted IT expert is frequently now not required
- Decrease value
- Clean records backup, so it’s usually accessible while you need it
- Correct at centralizing statistics storage in a secure, dependable way
How Does FAULT tolerance work?

Image Source: Link
Fault tolerance may be constructed into a gadget with the help of ensuring that it has no single point of failure. This requires that there’s no single thing that, if it stopped operating well, would cause the entire gadget to forestall working completely.
An average single factor of failure in a widespread system is the electricity deliver unit (PSU) which takes within the most important alternating present-day (AC) deliver and converts this into direct contemporary (DC) of numerous voltages to strength exclusive additives. If the PSU fails, then all the components it powers may also fail, generally main to a catastrophic failure of the whole system.
Structure In Fault Tolerance
![PDF] FTT-NAS: Discovering Fault-Tolerant Neural Architecture | Semantic Scholar](https://d3i71xaburhd42.cloudfront.net/eeb82451ff616cbc5c35d3b7b18f20f23eb7e081/3-Figure2-1.png)
Image Source: Link
The key reason for making fault tolerance is to keep away from the possibility that the capability of the machine ever becomes unavailable because of a fault in a single or extra of its components.
Fault tolerance is necessary for structures that can be used to guard people’s protection, and in systems on which security, information protection and integrity, and excessive fee transactions depend.
Redundancy
![PDF] FTT-NAS: Discovering Fault-Tolerant Neural Architecture | Semantic Scholar](https://d3i71xaburhd42.cloudfront.net/eeb82451ff616cbc5c35d3b7b18f20f23eb7e081/3-Figure1-1.png)
Image Source: Link
To eliminate a single point of failure and provide fault tolerance, fault-tolerant systems employ the concept of “redundancy.” This involves equipping the system with one or more redundant PSUs, which are not necessary for powering the system when the primary PSU functions normally.
However, should the primary PSU fail, the system can remove it from service and immediately switch to one of the redundant PSUs without interrupting the overall system’s functioning.
Variety
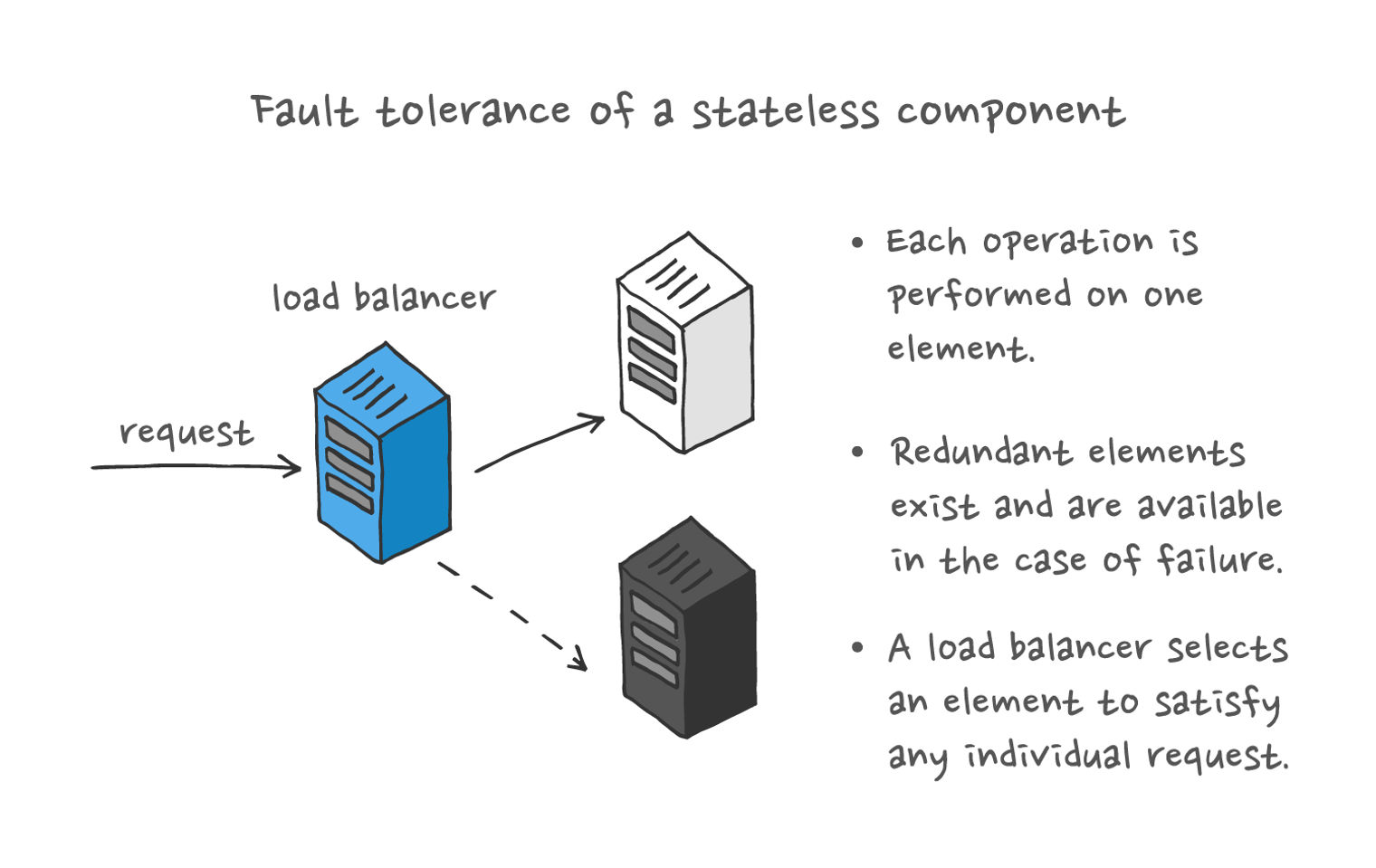
Image Source: Link
In some instances, it may not be possible to offer redundancy, and an instance of this is the primary electric delivery which normally comes from the general public strength grid. If the main power supply fails then it is usually not feasible to get admission to an alternative public electricity grid.
In this case, achieving fault tolerance can be done through redundancy, which typically means obtaining a power supply from an entirely different source – most likely an automatic backup power generator that activates in the event of a main power failure.
Replication
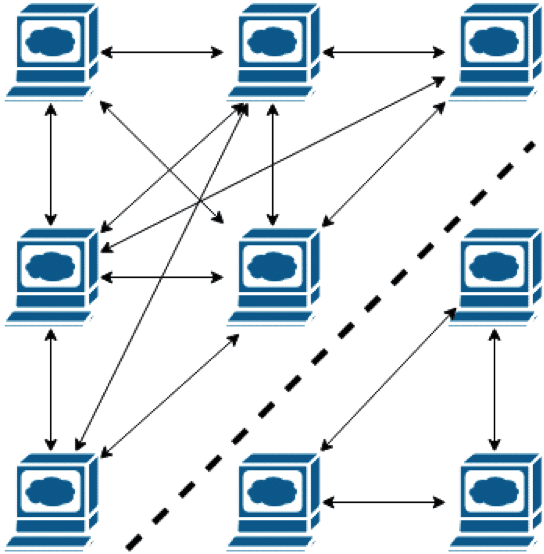
Image Source: Link
An extra complex manner to attain fault tolerance is through “replication.” This entails running more than one identical version of a device or subsystem and checking that they’re functioning constantly outcomes in identical results. If results range then a few procedures are referred to as much as deciding which gadget is defective.
Factors which consider in Fault Tolerance
Image Source: Link
Numerous elements have an effect on businesses’ selection to put in force a fault-tolerant system, including:
Cost
The largest downside of adopting a fault-tolerant method is the cost of doing so. Groups must assume carefully approximately the fee factors of a fault-tolerant or quite to be had machine.
Fault-tolerant structures require companies to have a couple of versions of system components to make sure redundancy, a greater device like backup turbines, and additional hardware. These components want ordinary protection and trying out. They also absorb precious space in information centers.
Reasonable Degradation
One way around the value of fault tolerance is to choose greater cost-powerful however decrease-pleasant redundant components. This technique can inadvertently grow maintenance and help costs and make the machine much less reliable.
RAID (Redundant Array of Independent Disks) for Data Protection
The RAID provides an effective data protection solution for businesses of all sizes by allowing multiple hard drives to function as one, larger device. RAID utilizes redundant disk arrays connected together to create one storage system and virtualizes the data across multiple disks making it more resilient against loss or damage caused by hardware failure, power outages, or other disruptions. It also optmimzes the reliability and performance of the system with its built-in redundancy functionality in case any single disk goes offline during operations.
You can implement RAID on various platforms needing reliable data protection, including basic network attached storage devices (NAS), servers, workstations, cloud systems, and enterprise-level systems.
By combining multiple separate physical disks into a single logical array of disks we are able to enable robust data resiliency through features like hot swapping new drives if there’s a drive malfunction; mirroring so there is always an up-to-date redundant copy; erasure coding for better fault tolerance; or striping which combines two or more small volumes spanning over large amounts of disks enabling fast loading times regardless of device capacity.
Hot Swapping and Hot Spare Drives for Continuous Operation
The Hot swapping and hot spare drives are essential components of continuous operation. Hot swapping is a process in which one can replace a non-functioning component with another functioning component as quickly and efficiently as possible without powering down the entire system. This can be extremely helpful in critical operations, such as medical settings, where they can keep the downtime to an absolute minimum. Hot spare drives are those that remain available at all times for immediate use while the primary drive undergoes maintenance or repairs.
By having these backup systems ready at all times, businesses are able to provide their users uninterrupted access to data resources, making it easier for them to complete their work faster with less disruption caused by downtime. Both hot swapping and hot spares ensure that businesses maintain high levels of reliability and availability when it comes to keeping important data secure and accessible 24/7 – something that is especially important in today’s increasingly digital world!
Network Redundancy and Load Balancing for NAS Reliability
The Network redundancy and load balancing are important aspects to consider when trying to maximize the reliability of a NAS (network-attached storage) system. Network redundancy refers to creating multiple copies of data stored on that particular NAS, while load balancing allows NAS systems to spread I/O operations among several servers for increased efficiency and performance. For instance, network redundancy allows access to backup copies if your company’s primary server goes offline due to a failure or outage.
Additionally, it keeps all business-critical information safe from physical damage from disasters such as flooding or fire. Load balancing maintains peak system performance by ensuring even distribution of tasks across available resources. By offloading some intensive workloads onto other nodes you decrease overall production time and cost because there’s less strain placed on individual machines resulting in fewer breakdowns and interruptions throughout the day – meaning fewer dollars spent on repairs for hardware problems caused by saturation overload scenarios.
Data Integrity and Error Correction in NAS Environments
Data integrity and error correction are two important factors to consider when working with networks attached storage (NAS) devices. To ensure that the data stored on these systems is reliable, it is important to implement strategies such as RAID levels, redundant array of independent disks (RAID). This helps protect against disk failures by creating striping of the data across multiple drives in order to provide redundancy if one drive fails.
You can also use error correction for any hardware that stores digital information, since bit errors or media defects can lead to corrupted files. This strategy involves using algorithms like Cyclic Redundancy Check (CRC) or Reed-Solomon encoding to detect and fix corrupt bits before they cause any permanent damage.
Additionally, using advanced wear-leveling techniques to distribute read/write operations across multiple cells can protect flash memory and hard drives from physical failure by minimizing wear patterns. By utilizing these technologies network administrators can create an environment where their data remains safe no matter what level of system and environmental degradation occurs around it.
Backup and Disaster Recovery Strategies for NAS Fault Tolerance
Network-attached storage (NAS) is a vital component of any successful organization’s IT infrastructure. With the right NAS fault tolerance strategies in place, organizations can maintain reliability and business continuity despite the failure of individual system components. Organizations can secure their long-term success against unforeseen circumstances by ensuring regular data backups are stored both onsite and offsite and establishing hot and cold disaster recovery systems for emergencies.
Furthermore, it’s important to keep hard drives up to date by regularly checking for issues like failing sectors or I/O errors so that performance issues don’t develop over time. Additionally, adding redundancy solutions such as RAID arrays into the NAS setup can protect against potential drive failure scenarios while also improving overall performance by striping files across multiple disks simultaneously or mirroring one drive to another.
Finally, utilizing cloud enabled services like secure remote access protocols or replication services allow you to further improve your ability input quickly recover from disasters without relying on physical assets alone. In order to maintain a reliable network storage environment day after day, businesses must make sure they have robust backup and disaster recovery strategies put into place ahead of time.
FAQs on NAS Reliability and Fault Tolerance:
1. How reliable are NAS systems compared to other storage solutions?
- NAS systems are generally considered highly reliable due to their redundant architecture and fault-tolerant features. They often incorporate redundant components such as power supplies, disk arrays with RAID configurations, and data replication mechanisms, which minimize the risk of data loss or downtime.
2. What are the key factors contributing to the reliability of NAS systems?
- Redundancy: NAS systems often feature redundant components such as power supplies, network interfaces, and disk arrays to ensure continuous operation in the event of hardware failures.
- Data Protection: Features like RAID (Redundant Array of Independent Disks) provide data redundancy and protection against disk failures by distributing data across multiple disks and enabling recovery in case of individual disk failures.
- Fault Tolerance: NAS systems utilize fault-tolerant designs and protocols to detect and recover from hardware or software failures automatically, minimizing downtime and data loss.
3. How do NAS systems handle hardware failures and ensure data availability?
- RAID Configurations: NAS systems employ various RAID levels such as RAID 1 (mirroring), RAID 5 (striping with parity), or RAID 6 (striping with double parity) to protect against disk failures. In the event of a disk failure, data can be reconstructed from redundant copies or parity information stored on other disks in the array.
- Hot Spare Drives: Some NAS systems support hot spare drives, which automatically replace failed disks in a RAID array to maintain data availability without manual intervention.
- Data Replication: NAS systems often support data replication features that replicate data between multiple NAS appliances or across geographically dispersed locations, providing additional redundancy and disaster recovery capabilities.
4. What measures can be taken to enhance fault tolerance in NAS deployments?
- Regular Maintenance: Perform regular maintenance tasks such as firmware updates, disk health checks, and system audits to identify and address potential issues before they lead to failures.
- Monitoring and Alerts: Implement monitoring tools that track the health and performance of NAS systems in real time and send alerts in case of anomalies or potential hardware failures.
- Disaster Recovery Planning: Develop comprehensive disaster recovery plans that include procedures for data backup, replication, and failover to secondary NAS systems or cloud storage in case of catastrophic failures or site-wide outages.
5. How can organizations ensure the high availability of NAS systems in mission-critical environments?
- Redundant Architecture: Deploy NAS systems in redundant configurations with multiple NAS appliances or clusters to eliminate single points of failure and ensure continuous availability.
- Load Balancing: Implement load-balancing mechanisms to distribute data access requests evenly across multiple NAS nodes, optimizing performance and preventing overloads on individual systems.
- Geographic Redundancy: Establish geographically dispersed NAS deployments with data replication between sites to maintain data availability and business continuity in the event of regional disasters or network outages.