NVIDIA® CUDATM technology takes advantage of NVIDIA GPUs’ massively parallel computing capacity. The CUDA framework is a ground-breaking massively parallel architecture that brings NVIDIA’s world-class graphics processor expertise to general-purpose GPU computing. CUDA-enabled GPUs are found in over one hundred million desktop and notebook computers, professional workstations, & supercomputer clusters, allowing applications written in the CUDA architecture to take advantage of them.
Developers are gaining substantial speedups in domains like medical imaging & natural resource exploitation and generating breakthrough applications in areas like image recognition as real-time HD video playing and encoding, thanks to the CUDA design and tools.
Developers are obtaining huge speedups in industries like medical imaging and mineral wealth exploitation and generating ground-breaking applications in areas like image recognition as true HD video playback & encoding using these technologies and techniques.
What’s more in store for you?
Standard APIs like OpenCLTM and DirectX® Compute and high-level programming languages like C/C++, Fortran, Java, Python, and the Microsoft.NET Framework enable this remarkable performance.
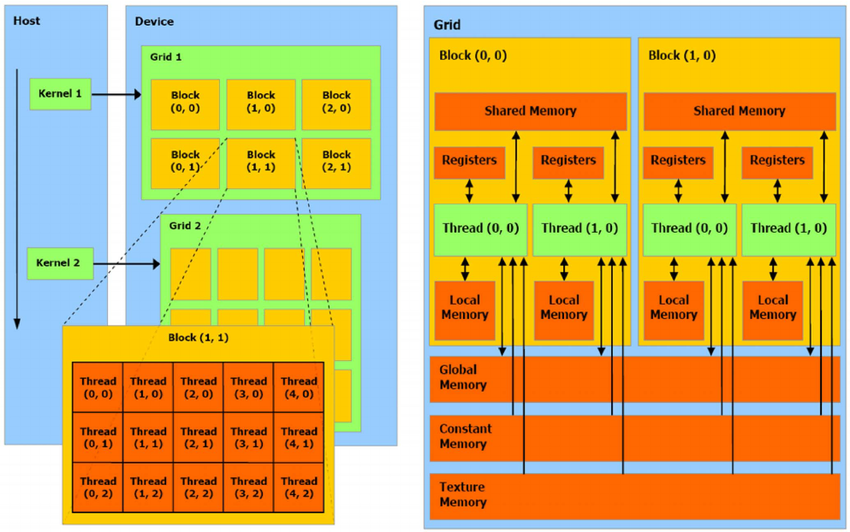
CUDA’s processing resources aim to aid in the optimization of performance in GPU use cases. Threads, task blocks, & kernel grids are three of the hierarchy’s most important elements.
A thread (or CUDA core) is a parallel processor that performs floating-point math calculations in an Nvidia GPU. A CUDA core handles all of the data that a GPU processes. CUDA cores can number in the hundreds or thousands on modern GPUs. Each CUDA core does have its memory registers that other threads do not have access to.
While the relationship between computing power & CUDA cores is not completely linear, the more CUDA core a GPU has, the more the computation power it has (provided everything else is equal). However, there are certain exceptions.
The CUDA Architecture is a graphics processing unit (GPU).
The CUDA architecture is made up of various components. Here is a list in green boxes:
- NVIDIA GPUs have parallel computation engines.
- Hardware start-up, setup, and other OS kernel-level support
- Consumer driver, which gives developers a device-level API.
- Parallel computing kernel and functions based on the PTX instructions set architecture (ISA).
CUDA Software Development Environment supports two programming interfaces:
- A device-level coding interface for applications that use DirectX Compute.
Set up the GPU, compute kernels, and use OpenCL or even the CUDA Drivers API directly and then read back the results.
- A programming interface allows an application to use the C programming language.
For CUDA, there is a runtime. Developers and designers use a tiny number of extensions to indicate which available features.
Instead of using the CPU, you must conduct computational functions on the GPU. Developers write compute kernels in the device-level programming interface. Use the kernel language provided by the API of choice to create separate files. Compute with DirectX.
You can use HLSL to write kernels. Kernels for OpenCL are built in a C-like language. “OpenCL C” is the name of the programming language. CUDA is a graphics processing unit. Developers write compute functions utilizing a language integration programming interface. In C and C++, The CUDA Runtime establishes the GPU and runs the code. Calculate functions. Developers can use this programming interface to reap the benefits of native features.
High-level languages like C, C++, Fortran, Java, Python, and many others are supported.
Using type integration & code integration to reduce the complexity of the algorithm and development costs:
- You can integrate and consistently use standard types, vectors, and user-defined types across both CPU-based and GPU (graphics processing) functions.
- Code integration enables you to invoke the same function from different functions performed on the CPU. The “C” in CUDA stands for a select set of extensions allowing developers to specify GPU tasks, determine which GPU memory to utilize, and outline how the GPU’s parallelization is employed. This aids in distinguishing functions executed on the CPU from those on the GPU. Thousands of software engineers already use the free CUDA development tools, first released in March 2007, and have already sold over 100 million Multi core GPUs. Help solve difficulties in various professional and personal applications, including video and image processing.
From oil and gas development, product development, and medical imaging, through processing & physics simulations,
Today, developers may utilize the CUDA architecture’s high performance by utilizing rich libraries.
APIs and several high-level languages are available on 32-bit and 64-bit Linux ™ Operating systems, macOS, and Windows.
Hierarchy of Memory
Separate memory areas exist for the CPU and GPU. This ensures that you need to process data either by GPU and transport it from the CPU to a GPU before the calculation can begin, and you must return the outputs of the calculation to the CPU once it completes the processing.
- Memory at the global level
- All threads and the host have access to this memory (CPU).
- The host manages global memory allocation and deallocation.
- You can use this to set up the data which the GPU would work with.
FAQs
1. What is NVIDIA CUDA Architecture?
NVIDIA CUDA (Compute Unified Device Architecture) is a parallel computing platform and application programming interface (API) model created by NVIDIA. It allows software developers and programmers to use a CUDA-enabled graphics processing unit (GPU) for general purpose processing (an approach known as GPGPU, General-Purpose computing on Graphics Processing Units). CUDA gives direct access to the GPU’s virtual instruction set and parallel computational elements, for the execution of compute kernels.
2. How does CUDA work?
CUDA works by providing a software environment that allows developers to write programs that can execute across many parallel cores on the GPU. It includes:
- CUDA Runtime and Driver APIs: For managing devices, memory, and program executions.
- CUDA Kernels: Functions written in CUDA C/C++ or another supported language, which execute on the GPU.
- CUDA Libraries: Pre-built functions for common numerical computations. Programs using CUDA offload computationally intensive kernels to the GPU, while the rest of the application remains on the CPU (Central Processing Unit).
3. What are the advantages of using CUDA for parallel computing?
The advantages of using CUDA for parallel computing include:
- Speed: Acceleration of computational tasks by harnessing the power of GPU parallel processing.
- Efficiency: Reduced processing time for applications involving large data sets or complex calculations.
- Flexibility: Support for multiple programming languages, including C, C++, and Fortran, as well as Python through interfaces like PyCUDA.
- Wide Application: Useful for a variety of domains such as machine learning, scientific computing, and financial modeling.
4. Can CUDA be used on any GPU?
No, CUDA is specifically designed to work with NVIDIA GPUs. This means that for a system or application to take advantage of CUDA acceleration, it must have a compatible NVIDIA GPU. CUDA cannot be used on GPUs from other manufacturers like AMD or Intel.
5. What types of applications can benefit from CUDA?
Applications that can benefit from CUDA typically involve large-scale mathematical computations or data processing tasks. This includes but is not limited to:
- Machine Learning and Deep Learning: For training and inference of neural networks.
- Scientific Computing: Simulations, computational biology, and physics.
- Data Analysis: Big data processing and analytics.
- Image and Video Processing: Real-time video encoding, image recognition, and computer vision.
6. How do developers get started with CUDA programming?
Developers can get started with CUDA programming by:
- Ensuring they have a CUDA-compatible NVIDIA GPU.
- Downloading and installing the CUDA Toolkit from NVIDIA’s official website, which includes the necessary compilers, libraries, and documentation.
- Learning CUDA programming by exploring NVIDIA’s documentation, tutorials, and sample code available in the toolkit and online resources.
- Experimenting with writing and optimizing basic CUDA kernels to understand parallel execution and memory management on the GPU.
7. What is the future of CUDA and parallel computing?
The future of CUDA and parallel computing looks promising, with continued advancements in GPU hardware and CUDA software. NVIDIA regularly updates the CUDA platform with new features, improved performance, and support for the latest GPUs. Parallel computing, in general, is becoming increasingly important for AI, machine learning, high-performance computing (HPC), and real-time processing tasks, suggesting that CUDA and similar technologies will remain vital tools for developers in these fields.