
When it comes to data, there’s a lot that can go wrong. Whether it’s incorrectly labeling training data, or forgetting to include some important variables in your code, mistakes can happen a lot. But what if you could predict those mistakes before they happened? That’s the power of machine learning, and it’s exactly what we’re going to be discussing in this blog post. We’ll be taking a look at logistic regression—one of the most commonly used methods in machine learning—and explaining how it can help you avoid errors in your data. So don’t miss out on this important piece of information; it could save you a lot of time and trouble down the road.
What is Logistic Regression?
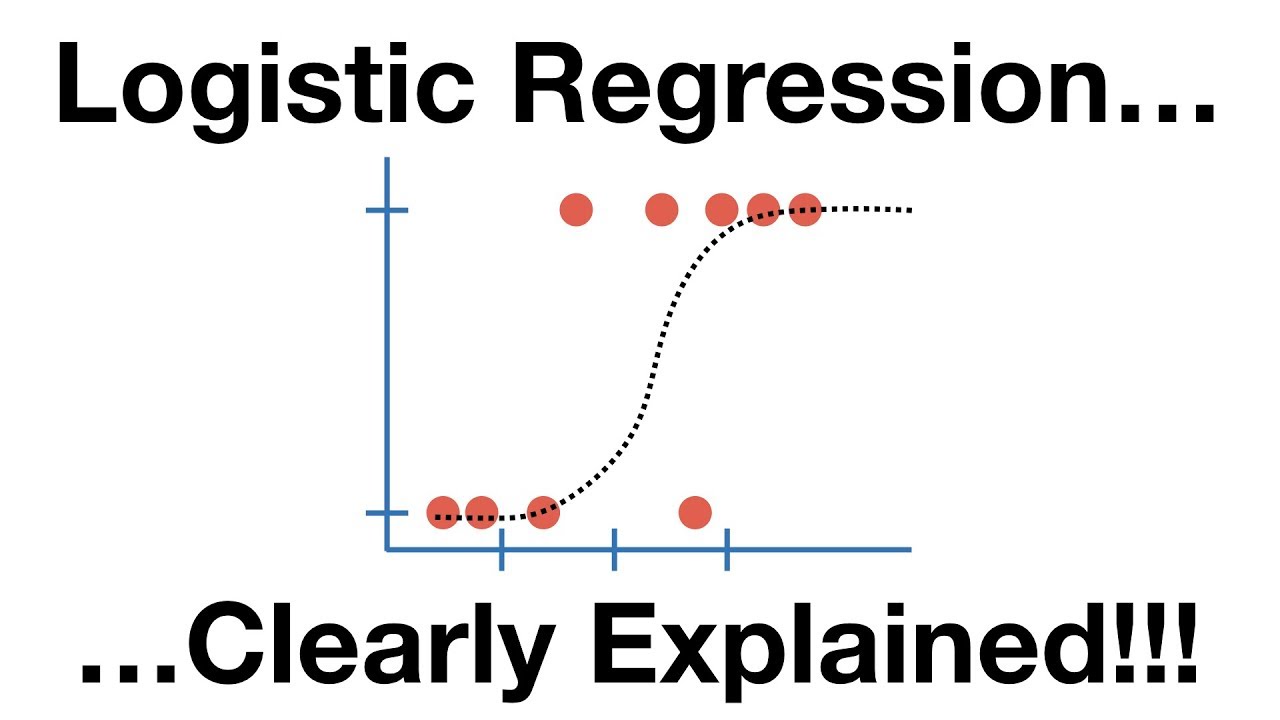
Logistic regression is a machine learning technique used to predict the probability of an event, such as a customer choosing a product. The algorithm uses input data, such as customer responses to questions about products, and predicts probabilities of events, such as whether a customer will choose a product.
How Does Logistic Regression Work?
Logistic regression is a machine learning technique that uses data to predict the probability of an event. The logistic regression model predicts the probability of an event by considering how likely a person is to have taken a certain action in the past.
The basic premise of logistic regression is that people are more likely to take specific actions depending on their current situation. For example, if you are trying to figure out which group of people is more likely to return your phone call, you can use logistic regression to predict which group of people is most likely to answer your call.
The most common way to use logistic regression is to predict probabilities. For example, you might want to know which groups of people are more likely to commit a crime. You can use logistic regression to predict the probability that someone will commit a crime based on their characteristics (such as age and gender).
Logistic regression can also be used for prediction purposes beyond predicting probabilities. For example, you could use it to predict whether or not someone will like a product. You could use it to predict how likely someone is to buy a product based on their characteristics (such as age and gender).
What are the Benefits of Using Logistic Regression?
Logistic regression is a supervised learning algorithm used in machine learning to predict the probability of an event. The algorithm trains on labeled data sets, where each instance corresponds to a category (e.g., class label for a person or product category for a shopping cart). The algorithm predicts the probability of an event, such as being in a given category, based on how often that event occurs in the training data.
The benefits of using logistic regression include:
- It is an effective tool for predicting probabilities
- It is fast and scalable
- It can be used with both numeric and categorical input data
- It is easy to implement
How to Implement Logistic Regression in Machine Learning Applications
Assuming you have some data and want to learn how to predict a category from it, there are a few options you can pursue:
- Linear regression,
- Neural networks, and
- Logistic regression.
In this blog post, we will focus on logistic regression because it is the most commonly used model in machine learning applications.
Logistic regression is a binary classifier that uses a linear predictor (a function that maps inputs to outputs). The decision rule for logistic regression is:
Predict y=1 if x>0 and y=0 otherwise.
The inputs to the model are vector of Predictors (features) and the output is a vector of Labels (classes). The simplest form of logistic regression takes only two predictors. However, more complex models may have up to 10 or more predictors.
To calculate the predictions for a given input, we first need to find the fitted values for each predictor. We can do this by fitting the model to the training data and then calculating the prediction error for each input. The prediction error measures how well the predicted value matches the actual value for that input in the training data.
Once we have found the fitted values for all predictors, we can use these values to generate predictions for new data samples. To do this, we first calculate an estimate of y using only those predictors that were actually used in fitting the model:
y_est = p(x|y) + (1-p)x_est
Next, we use the prediction error to calculate a Prediction score for each input:
prediction_score = prediction_error / (1 + prediction_error)
Finally, we use the Prediction score to generate a predicted label for each new data sample:
predicted_label = sigmoid(y_est * prediction_score)
Conclusion
In this article, we discuss what is logistic regression and how it can be used in machine learning. We also go over some of the key properties of logistic regression models. Moreover, we also provide a few examples to illustrate its use. Finally, we conclude with a discussion on how to apply logistic regression in practice.



