
We are now living in an age dominated by cloud computing. You can easily find everything available with a click on a button on the cloud, be it the data or the processing of the data. Various platforms are readily available for the devices of IoT if your organization is looking for more powerful options when it comes to processing. These are exceptionally helpful and compensate for the lack of power in the available local machines. This is done by processing everything in the cloud using Ai, which has amazing capabilities.
However, there are some concerns regarding sensitive data relying on the cloud. The concerns are there might be chances for it to leak, which might happen in the example of latency where the network is delayed in giving a response or not being available.
How IoT plays a crucial role?
The growth in devices that uses IoT has resulted in an increase in the usage of AI. Various smart devices surrounding us are often very smart but often lack the capacity and power to do powerful processing. Numerous devices are targeted and have limited hardware. In such situations, a model of AI can be deployed. Deployment of Ai in such a situation empowers local machines which are limited in their performance. Such devices can use the Cloud facility and run all the processing required to make the decision your organization requires, and all this can be done without a connection to services of the cloud.
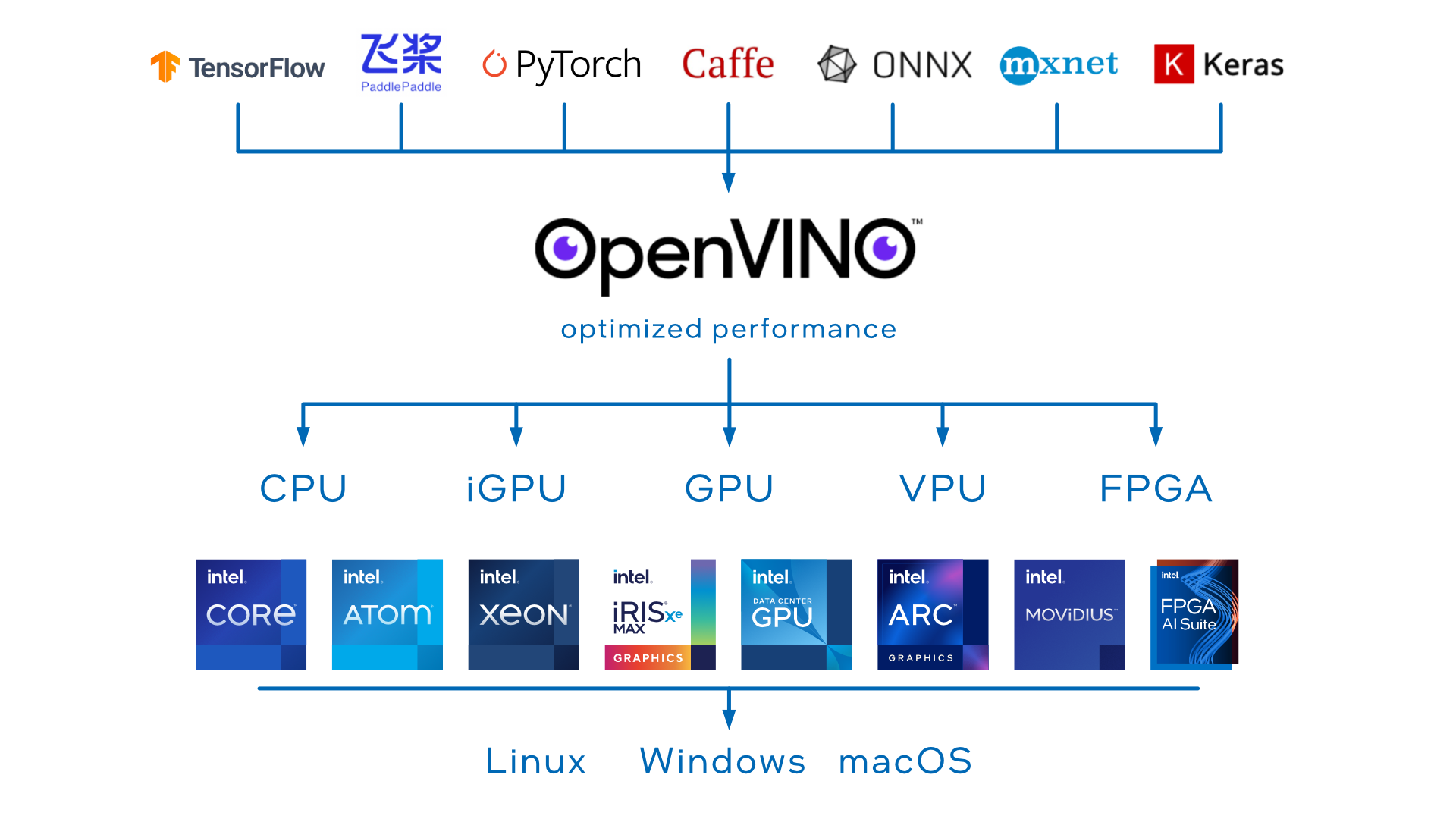
Open Visual Inferencing and Neural Network Optimization, or OpenVINO, is open-sourced software developed by the computing giant Intel. This goal is to optimize neural networks so that faster inferences can occur across all the hardware while keeping the API common. OpenVINO does so by optimizing the speed and the size of the model. This helps it to even if the hardware is limited.
However, it should be noted that this does not increase or improve the model’s accuracy. This optimization is similar to thrones done in the training step of the model. There might be situations when organizations using this setup might have to settle down for lesser accuracy to achieve high power of processing. For example, using an integer of 8-bit precision would be better than using the precision of a floating-point of 32-bit.
The workflow of OpenVino can be elaborated into 4 steps
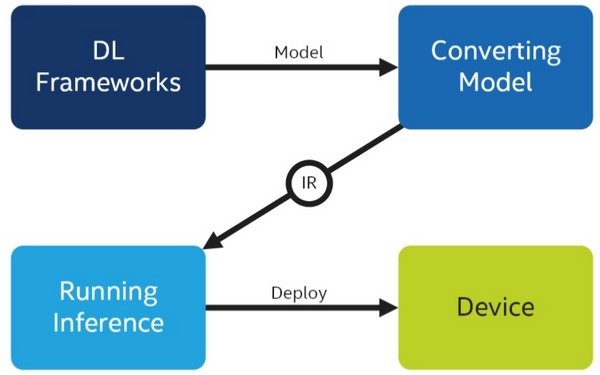
- Obtaining a model which is pre-trained.
- The pre-trained model needs to be further optimized with a model optimizer. Then an intermediate representation needs to be created,
- The inference engine is used for the inference, which is actual.
- The output of this process needs to be properly handled.
OpenVino
It is very easy to obtain a pre-trained model. One can obtain such from the model zoo of OpenVino. The organization can find various models that have already been trained to make them fit for immediate representation. For these models, no further optimization is needed. The organization can jump directly to inference using these models. This can be done by simply inputting the model into the existing engine of the framework. However, as an alternative, an organization can also find vicarious models that demand optimization before they can be transformed into an immediate representation.
Advances in deep learning and Ai have now made it possible to resolve tasks that are super complicated such as video processing intelligently or analyzing the texts, which would help enhance simple features such as user interface. This is done using functions that can be activated by voice, suggestions of texts, their corrections, and many other features.
How does it help?
The open vine toolkit helps speed up workloads such as audio speech, language, and computer vision. It is to be noted that the addition of the functions of Ai has its costs. These costs are not restricted to producing models using data science but also the capacity required to process the data during inference while increasing the application’s footprint.
It is so because it is a requirement that the model has to be redistributed along with the runtime binaries. The requirement of the memory depends upon the use case. The inference can demand substantial memory to execute the process. The toolkit has been designed to make deep learning inferences as light in weight as possible. This is achieved by improving the performance area and reducing the footprint of the final application, thus making it much easier when it comes to redistribution. The size of the toolkit can be considered substantial. That is because it is rich in various features.
FAQs
1. What is the Intel AI OpenVINO Toolkit?
The Intel AI OpenVINO (Open Visual Inference & Neural Network Optimization) Toolkit is a comprehensive toolkit designed to accelerate the development and deployment of computer vision and deep learning applications across Intel hardware platforms. It provides a set of tools, libraries, and pre-optimized kernels to optimize and deploy deep learning models for inference efficiently.
2. What are the key features of the Intel AI OpenVINO Toolkit?
Key features of the Intel AI OpenVINO Toolkit include:
- Model optimization: Tools to optimize deep learning models for inference across various Intel hardware architectures.
- Inference engine: A runtime engine for deploying optimized models on Intel CPUs, GPUs, FPGAs, and VPUs (Vision Processing Units).
- Support for multiple frameworks: Compatibility with popular deep learning frameworks such as TensorFlow, PyTorch, and ONNX.
- Model zoo: Pre-trained models for common computer vision tasks such as object detection, image segmentation, and classification.
- Heterogeneous execution: Ability to distribute inference tasks across multiple Intel hardware devices for improved performance and efficiency.
3. What types of applications can be developed using the Intel AI OpenVINO Toolkit?
The Intel AI OpenVINO Toolkit is suitable for developing a wide range of computer vision and deep learning applications, including:
- Object detection and recognition
- Facial recognition and emotion detection
- Gesture recognition and pose estimation
- Autonomous driving and vehicle detection
- Medical imaging and diagnostics
- Industrial inspection and quality control
4. How does the Intel AI OpenVINO Toolkit optimize deep learning models for inference?
The Intel AI OpenVINO Toolkit employs a variety of optimization techniques, including:
- Quantization: Reducing precision of weights and activations to improve computational efficiency.
- Model pruning: Removing redundant or low-impact parameters from the model to reduce size and computation.
- Fusion: Combining multiple layers or operations into a single optimized kernel for faster execution.
- Kernel optimization: Generating platform-specific optimized kernels for Intel hardware architectures.
5. What Intel hardware platforms are supported by the AI OpenVINO Toolkit?
The Intel AI OpenVINO Toolkit supports a wide range of Intel hardware platforms, including:
- Intel CPUs (Central Processing Units)
- Intel Integrated Graphics
- Intel Neural Compute Stick (VPU)
- Intel FPGA (Field-Programmable Gate Array)
6. Can I deploy models optimized with the Intel AI OpenVINO Toolkit in edge and IoT devices?
Yes, the Intel AI OpenVINO Toolkit is well-suited for deploying optimized models on edge and IoT (Internet of Things) devices. It provides support for lightweight inference engines and hardware accelerators such as Intel Neural Compute Stick and Intel Movidius VPU, enabling efficient deployment of deep learning models in resource-constrained environments.
7. How can I get started with the Intel AI OpenVINO Toolkit?
To get started with the Intel AI OpenVINO Toolkit, you can download the toolkit from the official Intel website and access documentation, tutorials, and code samples. Intel provides extensive resources to help developers install, configure, and use the toolkit effectively. Additionally, community forums and support channels are available for assistance and collaboration with other users.



