
In all industries, the exponential expansion of data quantities necessitates the development of novel storage technology. Cloud technology can spread documents, block storage, or cache across numerous physical servers for highly available data backup and disaster recovery. The networked power storage underpins Amazon S3 and large data pools with distributed computing data centers.
What is Distributed Storage, and how does it work?
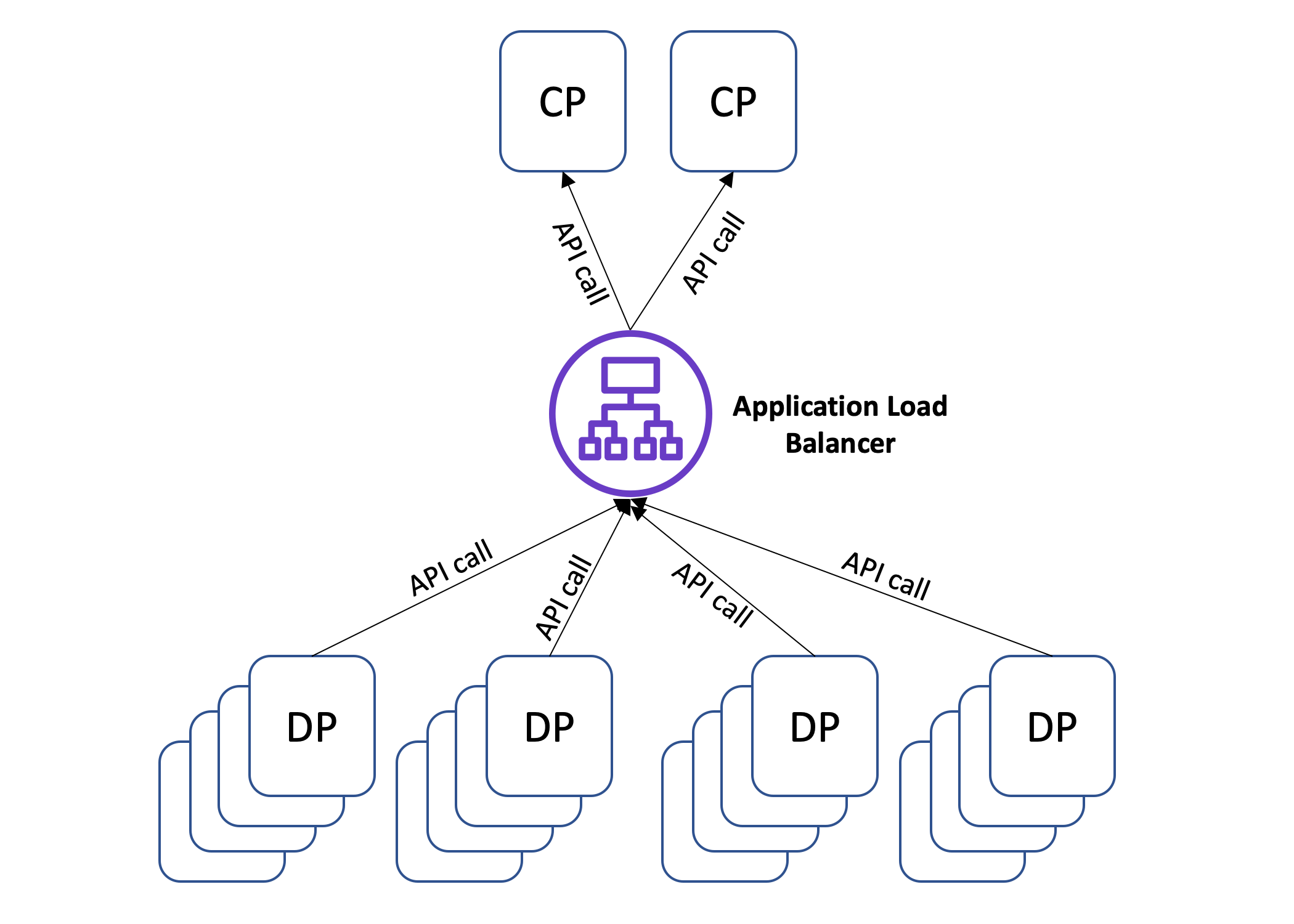
A distributed computing file system is a type of architecture. It allows data to be shared among numerous physical servers and, in some cases, multiple data centers. It normally consists of a storage cluster with data synchronization and coordination mechanism between cluster nodes.
Highly scalable cloud service storage technologies like Amazon S3 & Microsoft’s Cloud Blob Storage and distributed storage solutions like Cloudian Hyperstore rely on distributed storage.
Several types of data can be stored in distributed storage systems:
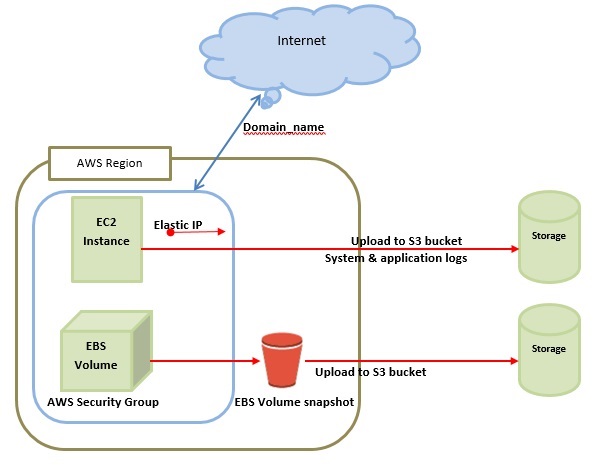
Image Source: Link
Files—a distributed computing allows devices to install a virtual disk, with the files spread over multiple workstations.
Block storage is a type of data storage that stores information in a volume called blocks. This is a performance-enhancing alternative to an archive structure of distributed computing. A cloud service Storage Area Network is a common dispersed block storage system (SAN).
Objects—in a distributed memory storage system, data is wrapped into objects with a unique Number or hashed.
There are various advantages of using a distributed storage system:
The distributed computing fundamental motive for spreading storage is to represent the predicted. It adds more storage space to the cluster by installing more storage nodes.
Redundancy—for high reliability, backup, and disaster recovery, distributed file systems can store several copies of the same data.
Cost—distributed storage allows you to store vast amounts of data on less expensive commodity hardware.
Performance—In some cases, distributed storage can outperform a single server, for example, by storing data closer to its users or allowing highly parallel access to big files.
Features and Limitations of Distributed Storage:
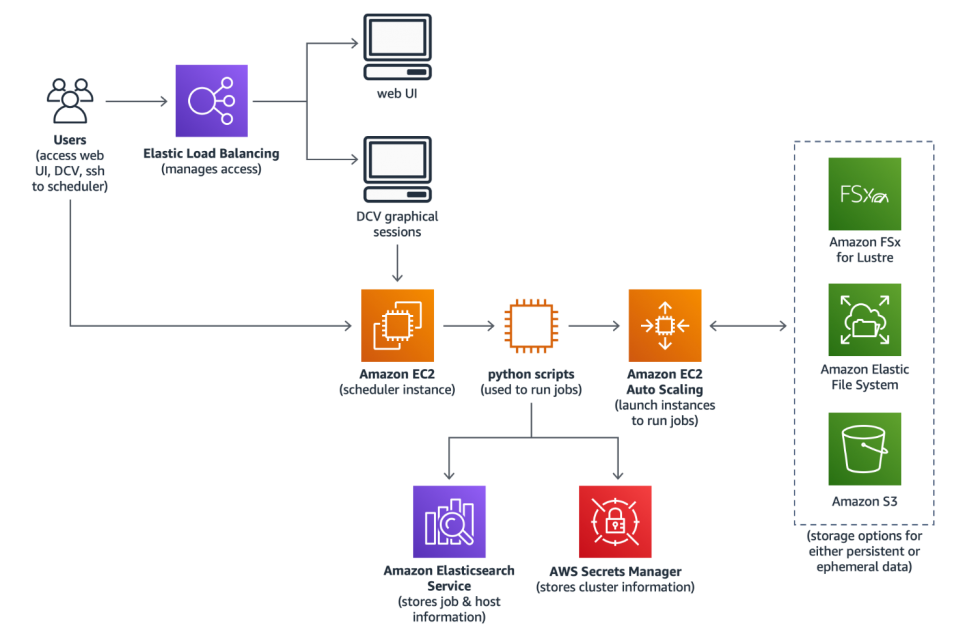
Image Source: Link
The majority of distributed computing storage systems include one or more of the following characteristics:
Partitioning is the ability to redistribute data among cluster nodes and allow clients to retrieve data from various nodes simultaneously.
Replication refers to duplicating the same piece of data across different cluster nodes while keeping the data consistent while clients update it.
Fault tolerance refers to keeping data accessible even if one or more nodes in a distributed storage cluster fail.
Elastic scalability allows data consumers to request additional storage space as needed. They can also request storage systestrators to scale storage up or down by adding or deleting storage units from the cluster.
The CAP theorem defines an intrinsic limitation for distributed storage systems. According to the theorem, a distributed system cannot sustain Consistency, Availability, and Partition Tolerance. At least a few of these three traits must be sacrificed. While many distributed storage systems ensure availability and partition tolerance, they sacrifice consistency.
An instance of a distributed file system is Amazon S3.
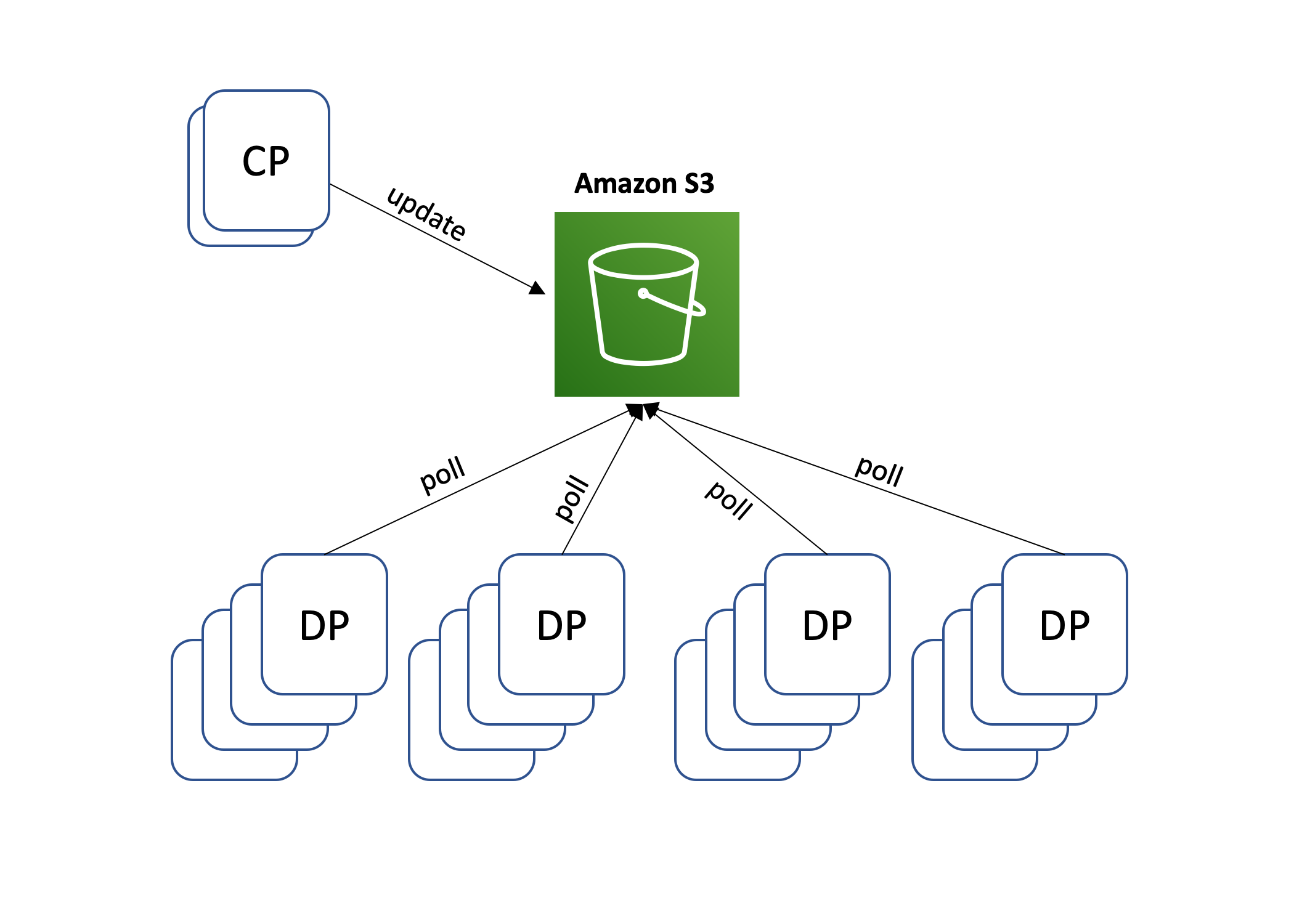
Image Source: Link
S3 stands for Amazon Simple Storage Service, a parallel processing storage system. Objects in S3 are made of metadata. The metadata is a moniker pair collection that offers information about the item, such as the most recent modification date. S3 accepts both standard marking and user-defined metadata.
Buckets are used to organize objects. Users of Amazon S3 must construct buckets and select which buckets to store and retrieve objects from. Users can organize their data using buckets, which are logical structures. The actual data may be spread among many file nodes in several Amazon AWS Availability Zones (AZ) in the same region behind the scenes. A bucket in Amazon S3 is always associated with a certain geographical area instance, Unit ed States 1 (North Virginia)—and items cannot leave that region.
A container, a password, and a version ID are used to identify each object in S3. The password is a one-of-a-kind identifier for each object in the bucket. Each object in S3 has numerous versions, as denoted by the edition ID.
Amazon AWS provide highly available partition tolerance because of the CAP theorem. However, it cannot ensure consistency. Instead, it proposes the following model of eventual consistency:
- If users PUT or Delete the data in Amazon S3, it is securely stored, but change may take some time to propagate throughout Amazon S3.
- Clients reading the data immediately after a change will still see the old copy of the data until the modification is disseminated.
- S3 guarantees atomicity: when clients read an object, they will see either the old or new copy, but never a damaged or partial version.
Cloudian’s On-Premises Distributed Storage
Cloudian HyperStore is the enterprise storage system with a completely distributed design that eliminates vulnerabilities and allows for easy scaling from thousands of Terabytes through Exabytes. It works flawlessly with S3 API.
The HyperStore software is based on three or more nodes, allowing you to replicate your items for high availability. It allows you to add as many hard disks as you require. It also allows the extra differences will immediately join the elastic storage pool.
Amazon EC2 Instances: Types and Configurations for Distributed Computing
Amazon EC2 instances, also known as virtual servers in cloud computing environments, are core building blocks for many distributed architecture services and applications. It offers a wide variety of instance types optimized to fit different use cases. These include memory-optimized instances, compute-optimized instances, GPU instances and storage-optimized instances. Each type of instance is equipped with different combination of processor cores (virtual CPU), RAM and other features. It also depends on the usage requirement such storage input/output operations or data throughput needs. Furthermore users can choose from multiple existing operating systems or distributions that Amazon EC2 provides when configuring an instance including Linux and Windows Server versions. With this range of options available it is possible to configure specialized solutions tailored specifically towards your application criteria.
Leveraging Auto Scaling in Amazon EC2 for Elastic and Scalable Distributed Computing
Auto Scaling in Amazon EC2 is an invaluable tool for creating highly elastic, scalable distributed computing solutions. Auto Scaling allows you to build applications utilizing a dynamic pool of resources that automatically increase or decrease the number of EC2 instances based on predetermined conditions and criteria. This enables you to scale your computing capacity up or down as needed with immediate effect, making it ideal for situations such as high compute loads during peak periods. Moreover, Amazon EC2 Auto Scaling helps maintain the desired level of performance over time by monitoring application health and responding to changes accordingly. When used effectively, organizations can optimize their IT infrastructure usage. It can also maintain optimal performance levels with minimal manual effort required from system administrators.
Distributed Data Storage and Management with Amazon S3
Distributed data storage and management has been instrumental in powering innovative applications and services for contemporary businesses. With S3, users are able to store, protect, securely manage and access data from anywhere in the world. As well as being incredibly reliable for all types of use cases. From web hosting to mobile application development, its low latency makes it an ideal choice for streaming large quantities of data worldwide.
By allowing developers to choose how much storage capacity they need at any given time without incurring additional charges or over-provisioning resources, Amazon S3 provides superior scalability compared to traditional storage solutions. Furthermore, with support for a wide range of protocols such as REST and SOAP along with industry-leading security features like encryption at rest via AWS Key Management Service (KMS), Amazon S3 enables organizations worldwide to leverage best practices when building their cloud infrastructure.
Integration of Amazon EC2 and S3 for Distributed Computing Workflows
Integration of Amazon EC2 and S3 for distributed computing workflows is a major development in the distributed computing field. It allows for quickly deploying and scaling applications, enabling higher levels of performance while reducing infrastructure costs. With their automated capacity management, EC2 and S3 simplify complex compute workflows by abstracting away resource provisioning from developers and allowing them to focus on their applications. By providing reliable cloud storage with S3, compute nodes can easily access data needed for computations without needing to store it on each node individually or waiting for lengthy transfer times over long distances.
This helps keep computing resources committed solely to current tasks instead of managing unnecessary overhead activities. Together these two services provide an efficient workflow where compute jobs are divided into smaller sections that can be processed across a network of machines using Amazon’s web service APIs. This enables scalability when faced with significant processing demands, which can reduce costs while increasing system capability.
Conclusion
Amazon EC2 and S3 have become highly popular cloud-based distributed computing solutions with increasing numbers of businesses taking advantage of their scalability, reliability, and security. By enabling virtual machines to be easily deployed and managed in a cost effective manner, Amazon provides enterprise level performance at a fraction of the cost that would be required for dedicated hardware. The ability to store data securely offsite has also been embraced by more organizations. It relieves them from having to manage their own physical infrastructures while gaining access to lightning fast storage capabilities. Ultimately, Amazon EC2 and S3 offer an effective balance between affordability, flexibility, control, and performance. This makes them ideal choices for many modern businesses looking for contemporary distributed computing solutions.



