This release will deal with the implementation of the neural network using Tensorflow.
Using the Titanic Dataset from kaggle
Notebook to check and run code: https://www.kaggle.com/code/tanavbajaj/neural-network-basic/notebook
Let’s start by importing the libraries
| import numpy as np import pandas as pd import tensorflow as tf |
Read the Data
| data= pd.read_csv(‘../input/titanic/train.csv’) |
Select the required data frames and by intuition class, fare, age and sex are the most important predictors.
This is known because higher class people were given priority over the lower class. Sex is important because women were given preference over men. Age becomes a predictor because children were also given preference.
So as per my intuition lower class men were most likely to die.
But we can’t rely on intuition only so let’s go for the machine learning algorithm.
| data = data[[‘Survived’, ‘Pclass’, ‘Sex’, ‘Age’, ‘Fare’]] data = data.dropna() target = data.pop(‘Survived’) |
As per the datasets out of 800 people around 500 people died and the rest survived.
Now that the NULL values have been dropped and the target is separated from the data time to build the machine learning pipeline.
One hot encoding on the categorical dataset and normalisation of the numeric dataset.
Normalisation is to make sure that the dataset fits between 0 and 1.
One hot encoding creates a new column for each category. All are filled with 0s and 1s. 1s refer to the existence of that category for the row.
So lets split the dataset into parts for the same
| categorical_feature_names = [‘Pclass’,’Sex’] numeric_feature_names = [‘Fare’, ‘Age’] predicted_feature_name = [‘Survived’] |
To feed the dataset to Tensorflow it must be pre-processed in a certain way.
The first task is to create the tensor dictionary
| def create_tensor_dict(data, categorical_feature_names): inputs = {} for name, column in data.items(): if type(column[0]) == str: dtype = tf.string elif (name in categorical_feature_names): dtype = tf.int64 else: dtype = tf.float32 inputs[name] = tf.keras.Input(shape=(), name=name, dtype=dtype) return inputs inputs = create_tensor_dict(data, categorical_feature_names) |
Here each column is assigned a particular TensorFlow datatype based on its current datatype and a dictionary is created to uniquely identify each column and its data type.
Next up is normalising the dataset
Before normalizing the features a helper function is needed to convert pandas dataframe to tenroflow floats and converts it into one big tensor.
| def stack_dict(inputs, fun=tf.stack): values = [] for key in sorted(inputs.keys()): values.append(tf.cast(inputs[key], tf.float32)) return fun(values, axis=-1) |
Next its time to normalise using Keras’s inbuilt normalizer.
| def create_normalizer(numeric_feature_names, data): numeric_features = data[numeric_feature_names]normalizer = tf.keras.layers.Normalization(axis=-1) normalizer.adapt(stack_dict(dict(numeric_features))) return normalizer |
Using the stack_dict and create_normalizer function time to create a dictionary in a way the normalizer can process it.
| def normalize_numeric_input(numeric_feature_names, inputs, normalizer): numeric_inputs = {} for name in numeric_feature_names: numeric_inputs[name]=inputs[name] numeric_inputs = stack_dict(numeric_inputs) numeric_normalized = normalizer(numeric_inputs) return numeric_normalizednormalizer = create_normalizer(numeric_feature_names, data)numeric_normalized = normalize_numeric_input(numeric_feature_names, inputs, normalizer)
|
Creating a way to store all the preprocessed dataset.
| preprocessed = [] preprocessed.append(numeric_normalized) |
Now the numeric part of the dataset has been normalised it is time to do one hot encoding to the categorical features.
Here we iterate through the columns and find the string and integer type of columns and convert into the one-hot encoded columns for strings. Then we do the same for integer values. To do this placeholders from the input dictionary created above are taken.
At the end one hot encodings are returned from the function.
| def one_hot_encode_categorical_features(categorical_feature_names, data, inputs): one_hot = [] for name in categorical_feature_names: value = sorted(set(data[name])) if type(value[0]) is str: lookup = tf.keras.layers.StringLookup(vocabulary=value, output_mode=’one_hot’) else: lookup = tf.keras.layers.IntegerLookup(vocabulary=value, output_mode=’one_hot’) x = inputs[name][:, tf.newaxis] x = lookup(x) one_hot.append(x) return one_hot |
Next add one hot encoded data to the preprocessed one.
| one_hot = one_hot_encode_categorical_features(categorical_feature_names, data, inputs) preprocessed = preprocessed + one_hotpreprocesssed_result = tf.concat(preprocessed, axis=-1) |
Keras now performs its own preprocessing before the model is constructed
| preprocessor = tf.keras.Model(inputs, preprocesssed_result) |
Now that the dataset has been preprocessed it is time to build the model.
Build the Neural Network
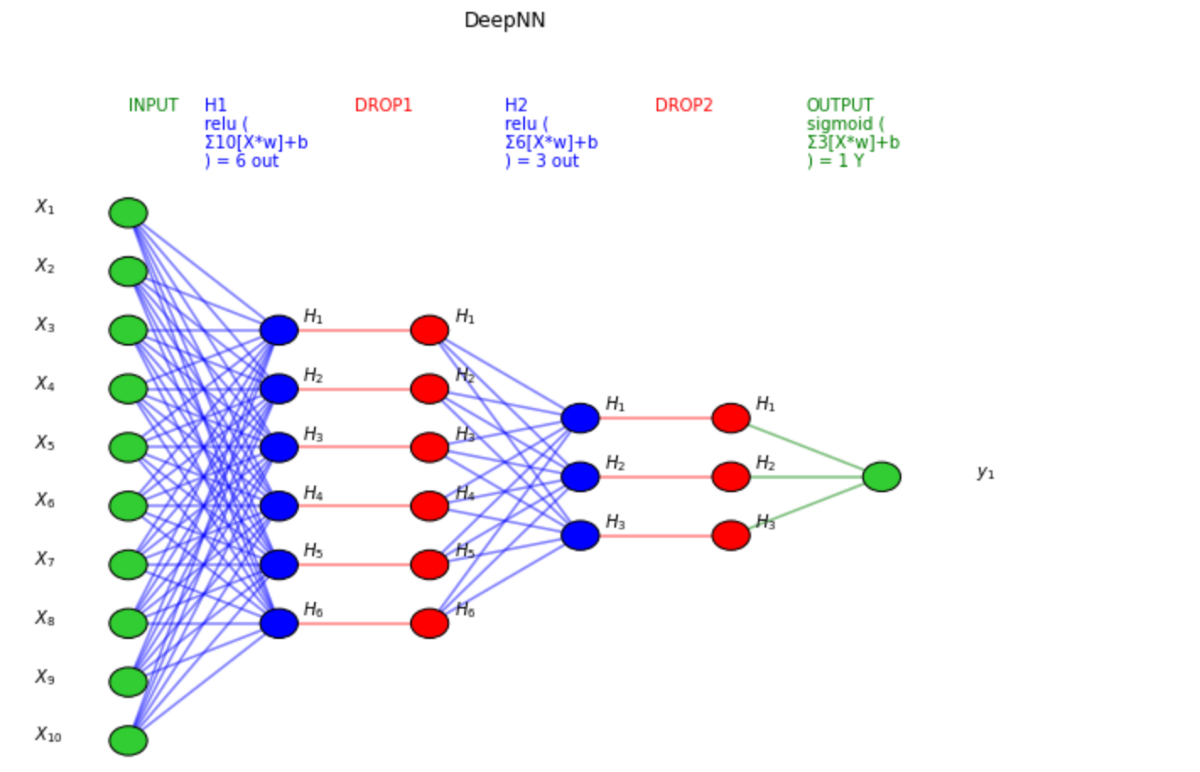
Using Keras Sequential its time to define the neural network. We will be using 2 dense hidden layers with 10 neurons each and apply the ReLU activation function. For the output layer sigmoid activation function is used especially because this is a binary classification problem.
| network = tf.keras.Sequential([ tf.keras.layers.Dense(10, activation=’relu’), tf.keras.layers.Dense(10, activation=’relu’), tf.keras.layers.Dense(1) ]) |
Now the preprocessor and network are tied together
| x = preprocessor(inputs) result = network(x) model = tf.keras.Model(inputs, result) |
Finally the entire model is compiled using the Adam optimizer ( Adam is generally used as default) along with binary cross as loss function and accuracy as the evaluation function.
| model.compile(optimizer=’adam’, loss=tf.keras.losses.BinaryCrossentropy(from_logits=True), metrics=[‘accuracy’]) |
Lets split the dataset into test and training datasets and run the model.
| from sklearn.model_selection import train_test_split
train_data, val_data, train_target, val_target = train_test_split(data,target, train_size=0.8) |
Once the model is run lets see th accuracy it gives.
| results = model.evaluate(dict(train_data), train_target, batch_size=128) print(“test loss, test accuracy:”, results) |
We see an 80% accuracy here.
FAQs
What libraries are commonly used to implement neural networks in Python?
The most popular libraries for implementing neural networks in Python are TensorFlow and PyTorch. TensorFlow is an open-source machine learning framework developed by Google, while PyTorch is maintained by Facebook’s AI Research lab. Other notable libraries include Keras, which is integrated with TensorFlow and provides a user-friendly interface for building neural networks, and scikit-learn, which includes basic neural network functionality as part of its machine learning toolkit.
How do I install TensorFlow or PyTorch to start building neural networks?
You can install TensorFlow using pip, Python’s package manager, with the following command:
pip install tensorflow
For PyTorch, you can install it using pip as well:
pip install torch torchvision
Make sure you have the appropriate version of Python installed on your system.
What are the basic steps to implement a neural network in Python?
The basic steps to implement a neural network in Python are as follows:
- Import the necessary libraries (e.g., TensorFlow, PyTorch).
- Define the architecture of the neural network, including the number of layers, the number of neurons in each layer, and the activation functions.
- Prepare the input data and preprocess it if necessary.
- Train the neural network using the training data and an optimization algorithm (e.g., gradient descent).
- Evaluate the performance of the trained model using test data and appropriate metrics.
Can you provide an example of implementing a simple neural network in Python?
Sure! Here’s a basic example of implementing a neural network using TensorFlow:
import tensorflow as tf
# Define the architecture of the neural network
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation=’relu’, input_shape=(784,)),
tf.keras.layers.Dense(64, activation=’relu’),
tf.keras.layers.Dense(10, activation=’softmax’)
])
# Compile the model
model.compile(optimizer=’adam’,
loss=’sparse_categorical_crossentropy’,
metrics=[‘accuracy’])
# Train the model
model.fit(train_images, train_labels, epochs=10)
# Evaluate the model
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(‘Test accuracy:’, test_acc)
Are there any resources or tutorials available to help me learn how to implement neural networks in Python?
Yes, there are plenty of resources and tutorials available online to help you learn how to implement neural networks in Python. You can start with the official documentation and tutorials provided by TensorFlow and PyTorch. Additionally, there are numerous online courses, books, and video tutorials covering various aspects of neural network implementation with Python. Websites like Coursera, Udemy, and YouTube offer a wealth of resources for beginners and advanced learners alike.