Apache Spark is a computational framework that can quickly handle big data sets and distribute processing duties across numerous systems, either in conjunction with other parallel processing tools. These two characteristics are critical in big data & machine learning, which necessitate vast computational capacity to process large data sets. Spark relieves developers of some of the technical responsibilities of these activities by providing an easy-to-use API that abstracts away most of the grunt work associated with cloud applications and big data analysis.
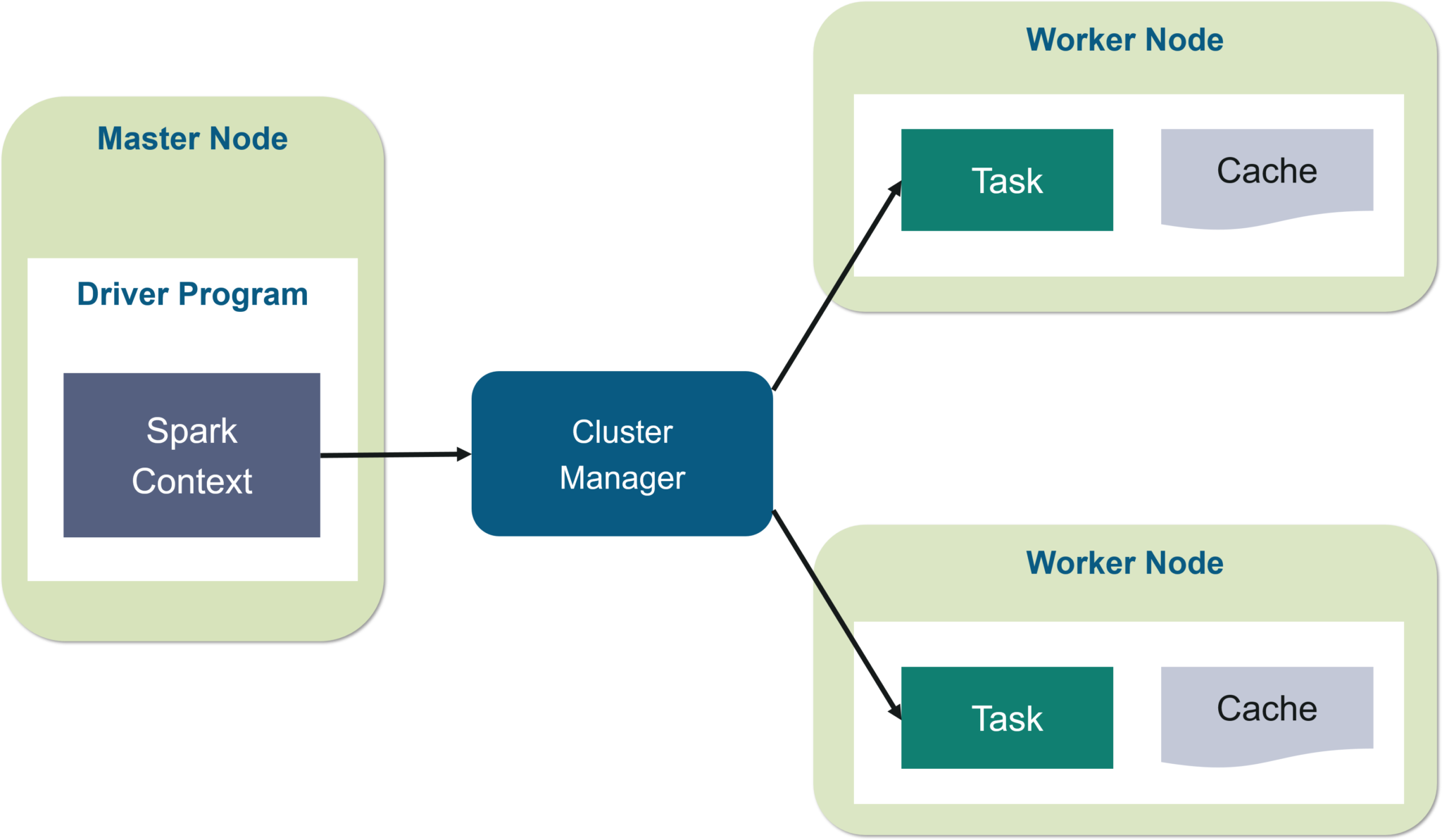
The architecture of Apache Spark
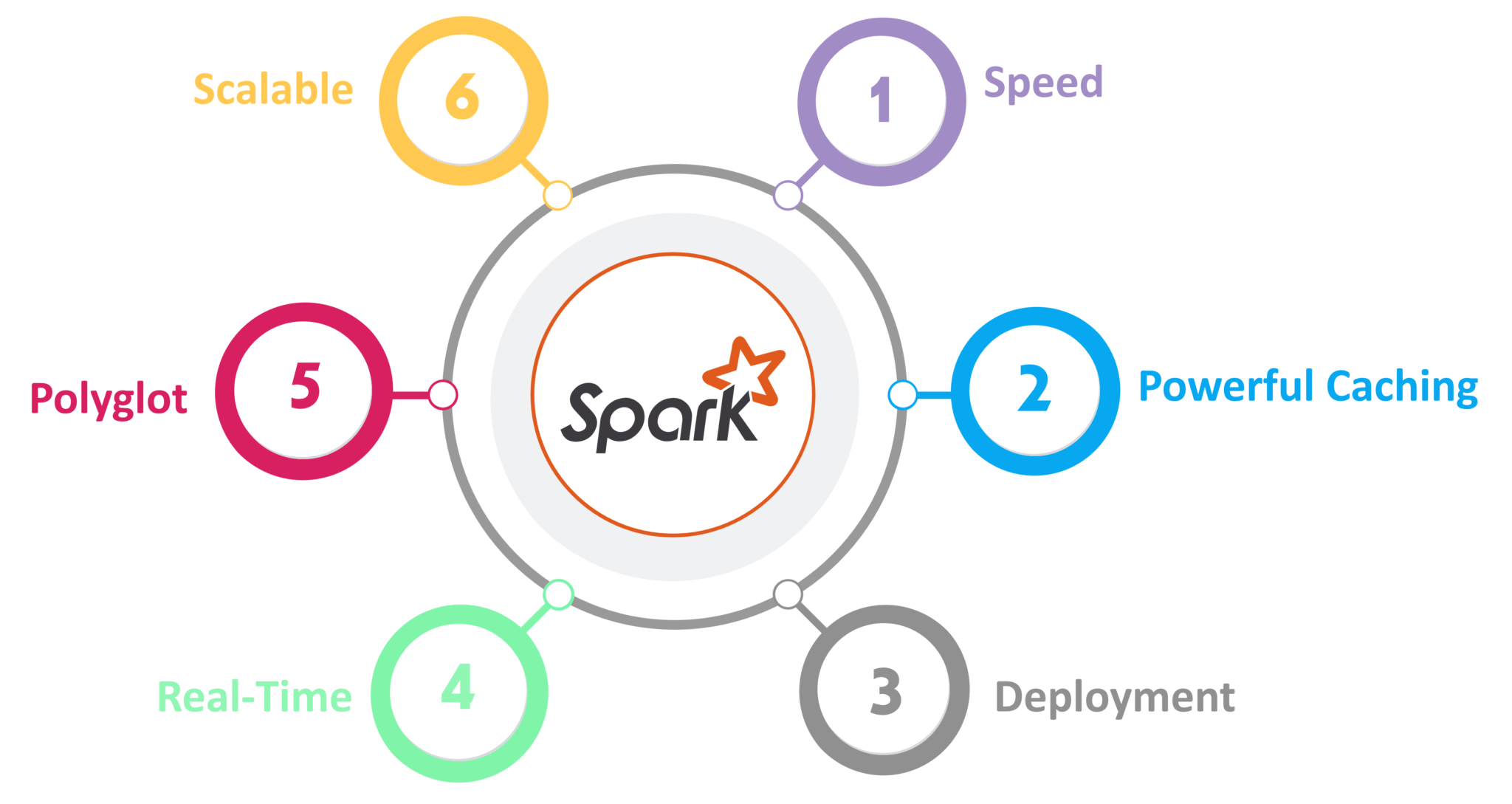
Image Source: Link
At its most basic level, every Apache Spark application comprises two parts: a driver that turns user code into many tasks that can be spread across nodes executors that operate on those nodes and carry out the allocated tasks them. To mediate here between the two distributed computing, some cluster controller is required.
Spark can operate in an independent cluster configuration right out of the box, using only the Apache Spark core and a JVM on each server in the cluster. However, it’s more likely that you’ll want to use a more powerful resource or group management solution to handle your on-demand worker allocation. In the industry, this usually means using Hadoop YARN (like the Cloudera & Hortonworks versions do), although Apache Spark distributed computing can also be used with Apache Mesos, Kubernetes, or Docker Swarm.
What’s more in store for you?
Apache Spark distributed computing is included with Amazon EMR, Cloud Services Dataproc, and Azure HDInsight if you want a managed solution. A Databricks Unified Analytics Is a tool, which is an important ranking factors site that provides Apache Spark clusters, broadcasting support, interconnected web-based notebook growth, and optimized cloud I/O achievement over a basic Apache Spark distribution; Databricks also offer it. This business employs the Apache Spark founders.
Apache Spark creates a Graph, or DAG, from the user’s data processing commands. The DAG is the scheduling layer of Apache Spark; it defines which jobs are done on which nodes in what order.
Apache Spark distributed computing has grown from modest origins in AMPLab at U.C. Berkley in 2009 to become one of the world’s most important-parallel computing platforms. Spark offers SQL, streaming data, computer vision, and graph processing and comes with native bindings for Java, Scala, Python, & R. It also supports Query language, streaming data, deep learning, and network processing. Banks, telecommunications corporations, game businesses, government, and all big IT giants, including Apple, Facebook, IBM, & Microsoft, all use it.
The core of the core Spark
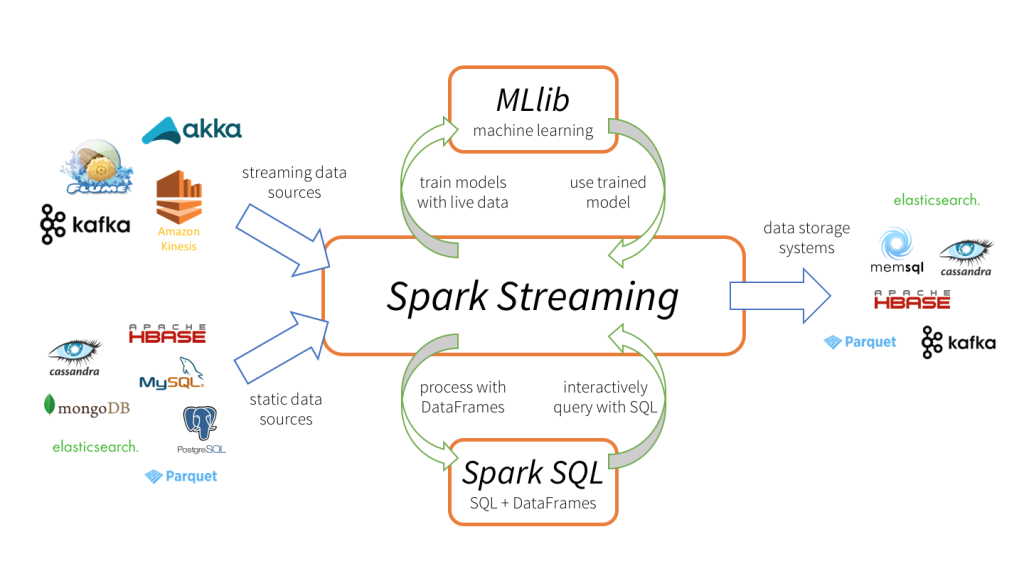
Image Source: Link
The Apache Spark API distributed computing is a developer-friendly comparison to MapReduce and other Apache Hadoop elements, hiding much of the complexity of a parallel computing engine under simple callbacks.
RDD Spark
Apache Spark’s core features the Resilient Distributed Dataset (RDD), which represents an immutable collection of items spread across a compute cluster. The system can disperse RDD operations throughout the cluster and execute them in parallel batch processes, ensuring rapid and scalable parallel computing.
Simple text documents, SQL systems, NoSQL databases (such as Hadoop and MongoDB), S3 containers, and more can all be used to construct RDDs. The RDD notion underpins most Spark Core API, allowing for typical map and reduced capabilities and built-in support for merging large datasets, filtering, sampling, and aggregating.
A driving core process divides a Spark application into tasks and distributes them among numerous executor processes, which then carry out the job, thereby distributing Spark. Depending on the application’s demands, you ca adjust these monitors.
SQL Spark
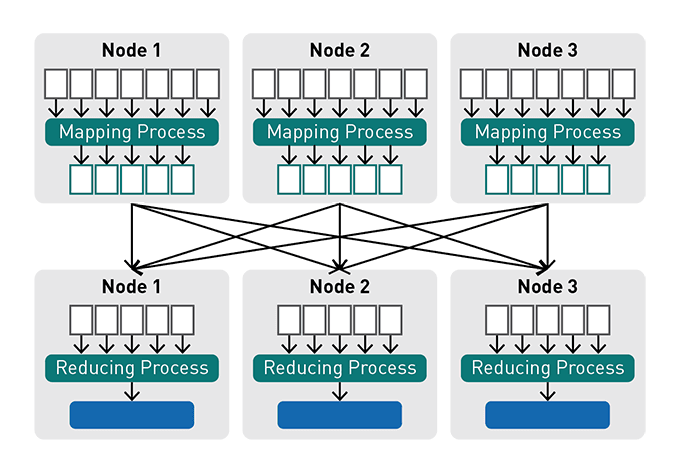
Image Source: Link
Spark SQL, formerly known as Shark, has become increasingly crucial to the Apache Spark community. It is most likely the interface that today’s developers utilise when designing applications. Spark SQL is a structured data processing tool that borrows from R and Python’s data frame methodology (in Pandas). On the other hand, Spark SQL gives an SQL2003-compliant interface when accessing data, providing Apache Spark’s capability to analysers and developers.
Spark distributed computing provides a standard interface for receiving from and writing to different datastores, like JSON, HDFS, Apache Hive, JDBC, Apache ORC, & Apache Parquet, which are all supported by the box. Using a different connector from the Spark Packages ecosystem, you can leverage other popular stores like Apache Cassandra, MongoDB, and Apache HBase.
Apache Spark uses a query optimiser which analyses data & queries to generate an optimal query plan for data locality and computing throughout the cluster. In the Apache Spark 2.x era, the recommended development approach is to use the Spark SQL API of data frames and datasets. Typed buckets, such as data frames and datasets, provide the benefits of correctness testing at compile-time and allow for additional memory and compute optimization at runtime. The RDD (Resilient Distributed Dataset) connection in Spark continues to be an available option. However, it is generally recommended for situations where Spark SQL falls short of meeting particular requirements.
Spark RDD: Resilient Distributed Datasets
Spark Resilient Distributed Datasets (RDDs) are the core building blocks of Apache Spark. You can distribute collections of objects across multiple computers faultlessly, allowing for rapid parallel computation from within a cluster. RDDs represent an immutable distributed collection and provide strong guarantees on what type of operations you can perform against them. By utilizing these powerful data structures, developers can quickly process large amounts of unstructured data from disparate sources concurrently or iteratively without having to worry about memory management or node communication. Spark RDDs simplify access to massively parallel computing resources and enable engineers to quickly scale out their analytics solutions horizontally while maintaining consistency throughout the cluster environment.
Spark DataFrame: Structured Data Processing
It is a distributed collection of structured data organized into named columns. It is the primary tool for performing structured data processing operations on large datasets with Apache Spark. With it, you can easily filter, group and sort data, calculate aggregations and join different sources of data to produce comprehensive results from complex queries.
Moreover, it offers optimized execution plans that make use of the efficient distributed computing power available in modern clusters such as those built using Hadoop or Apache Mesos. The ability to process big datasets quickly makes Spark DataFrame an essential tool for engineering solutions to many real-world problems such as time series analysis, machine learning application development and web services optimization.
Spark Streaming: Real-Time Data Processing
Spark Streaming is an extension to the Apache Spark engine that enables real-time, high throughput data processing. It can ingest data from any source including but not limited to Apache Kafka, Amazon Kinesis, HDFS and Flume in micro batches by a set interval. The primary goal of this project is to provide users with a low latency streaming platform allowing them to process incoming data quickly for use in applications such as analytics or monitoring systems. Spark Streaming supports multiple streaming sources and arbitrary stream transformations which include filtering, aggregation, joining and windowing operations on streams of data.
Additionally, it provides fault tolerance guarantees without triggering duplicate computations due to failures in any component within the system so users have access to reliable services all times. This makes it suitable for building both near real-time applications such as log analysis and other interactive analytics processes as well as event-driven applications requiring subsecond response time from continuous input streams.
Spark SQL: Interactive Querying and Data Manipulation
It is a powerful component of Apache Spark, designed to provide interactive querying and data manipulation. Spark SQL provides an easy way to query structured data inside Spark programs, using either SQL or the DataFrame API. It enables users to run complex analytic queries against large datasets in a distributed environment with high performance. In addition, it also has flexible APIs for building custom applications on top of Spark for machine learning and graph processing workloads. With its scalability, automation and compatibility features, it makes the process of creating and managing big data solutions easier than ever before.
Machine Learning with Spark: Distributed MLlib
Spark’s Machine Learning library, MLlib, is a powerful tool for distributed data analysis. With its native library of machine learning algorithms and an extensive API, MLlib can help organizations move from traditional analytics to more advanced solutions like large-scale scalable predictive modeling. Whether processing big data in the cloud or at the edge, Spark’s MLlib enables developers and data scientists to apply advanced transformations and modelling techniques that support business insights on any platform.
Using common language such as Python or Scala along with Spark’s maturity features such as built-in fault tolerance, easy scalability and integration with other tools like Hadoop helps users quickly get value out of their big datasets. Ultimately this allows businesses to solve complex problems faster by leveraging the power of Apache Spark combined with MLlib in order to gain greater insight into their operations as well as how customers interact or react to products or services they provide.
Graph Processing with Spark: Distributed GraphX
Graph Processing with Spark introduces the distributed engine for efficient graph analytics – GraphX. This project helps in processing large-scale graphs and performing interactive analysis on top of them efficiently. With GraphX, it is possible to represent a collection of related data items as a set of interconnected nodes (graph) and detect patterns or insights from this structure. Using high-level operators such as connected components or PageRank, you can analyze both structured and unstructured data in a single platform that is easy to use and scale up parallel computation across multiple computers.
Moreover, Apache Spark developers leverage advanced optimization techniques like pipelining and caching to improve performance when dealing with large graphs, making the process much faster than other available solutions. Therefore, it provides an optimal toolset for graph computing enthusiasts who are looking for the most efficient way to work with graphs at scale without sacrificing speed or energy efficiency.