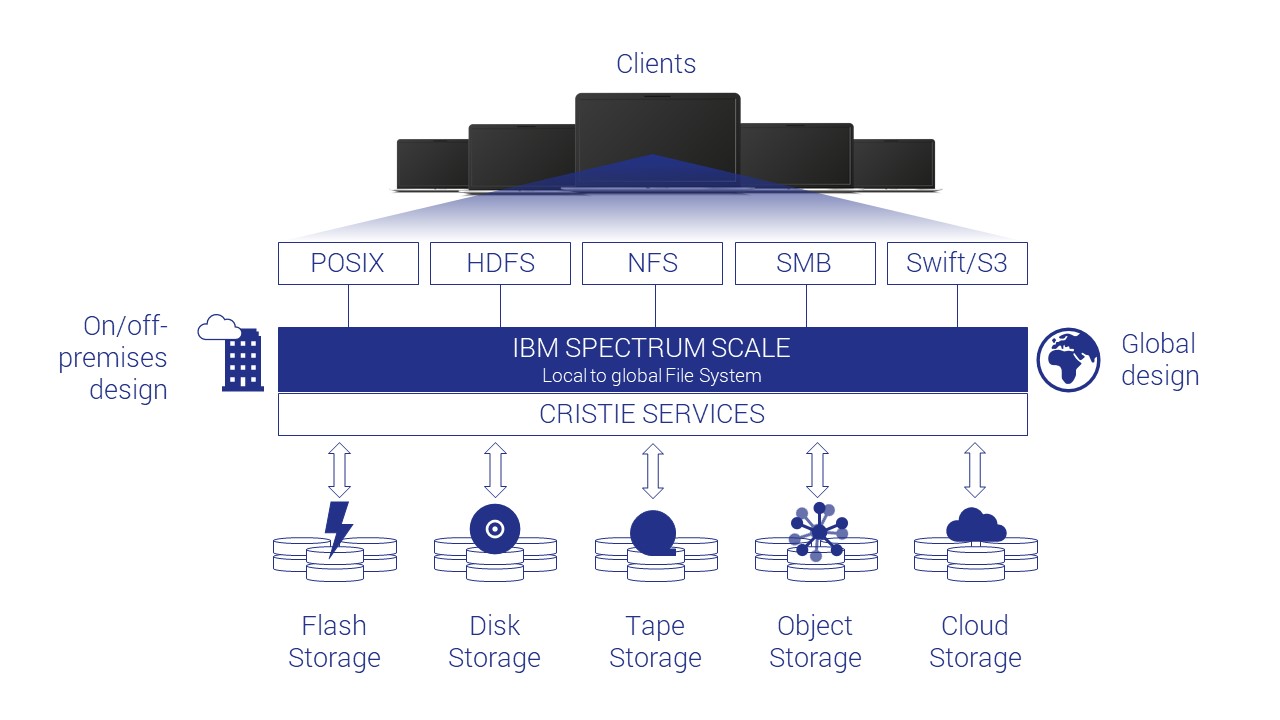
IBM Spectrum Scale data protection and disaster recovery
The IBM Spectrum Scale installation should be protected against data loss to ensure that operations continue after a malfunction.
- Data loss can be avoided by safeguarding four types of critical data:
- Data on cluster configuration
- Data about file system configuration
- Contents of the file system (user data, metadata, configuration)
- Protocol configuration information
Cluster configuration data is administrative information that links nodes, addresses, networks, and software installations on each node. System administrators should save the following configuration information:
The output of the mmlscluster command ensures that this data can be rebuilt if necessary. Depending on the repository type, the CCR backup or the mmsdrfs file is used.
File system configuration data includes a wide range of information about all of the file systems in the cluster. To safeguard this information, use the mmbackupconfig command for each file system and save the output files for later use. This configuration data specifies which discs are associated with which file systems as NSD components, how much storage is in use, the filesets defined, the quotas defined, and other useful configuration data that describes the file system structure. The file data in the user files are not included. User file data is the most basic and frequently changing information that requires protection.
IBM Spectrum Scale GUI Overview

The IBM Spectrum Scale management GUI makes it simple to configure and manage the IBM Spectrum Scale system’s various features.
The IBM Spectrum Scale management GUI allows you to perform the following critical tasks:
- Monitoring the system’s performance across multiple dimensions
- System health monitoring
- Creating and administering file systems
- Make file sets and snapshots
- Object, NFS, and SMB data export management
- Creating administrative users and assigning them roles
- Creating object users and assigning them roles
- Quotas for the default, user, group, and files
- Making and managing node classes
- Monitoring capacity details at multiple levels, including the file system, pools, file sets, users, and user groups.
- Monitoring and administration of the system’s different services
- Remote cluster monitoring
- Setting up a call home
- Setting up and monitoring thresholds
- Creating as well as managing custom node classes
- Setting up authentication process for NFS as well as SMB consumers.
You can use the IBM Spectrum Scale management API to create scripts that automate time-consuming cluster management tasks. These APIs enable integrating and then using the IBM Spectrum Scale system.
The IBM Frequency band Scale management API is a REST-style interface that allows you to manage IBM Spectrum Scale cluster assets. It operates over HTTPS and frames data within HTTP requests and responses with JSON syntax.
The GUI stack is used to implement the IBM Frequency Scale management API. The API requests, as well as commands, are managed and processed by the GUI server.
IBM Spectrum Scale data backup options
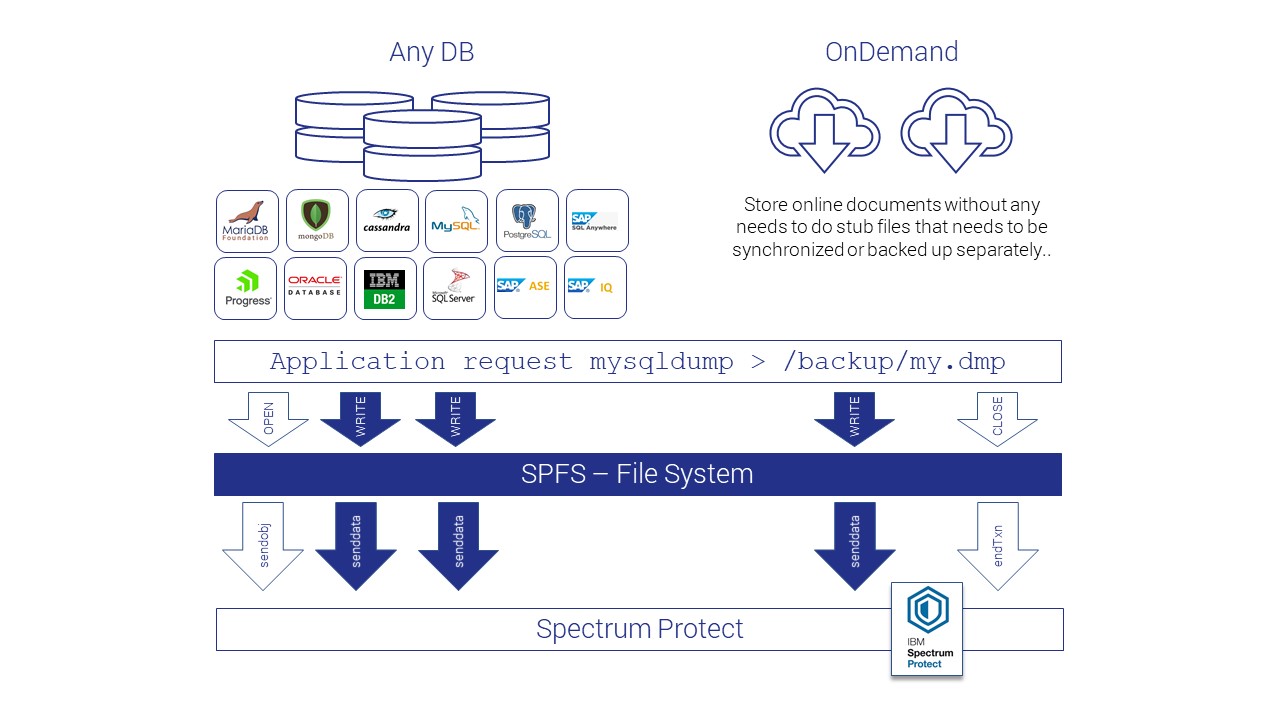
Creating a data backup
IBM Spectrum Scale makes a backup copy of the data within the system.
Organizations typically create point-in-time data snapshots routinely, such as on a monthly or fortnightly basis, for use in file recovery when the original data is lost. To back up user data from a GPFS file system or specific fileset to a TSM domain controller or servers, they utilize the mmbackup command. Please note that the mmbackup command is applicable only to file systems managed by the local cluster.
Data recovery
The scheme can reinstate data that has become subverted due to user inconsistencies, hardware failure, destruction, or even bugs in other business applications.
IBM Spectrum Scale data mimicking
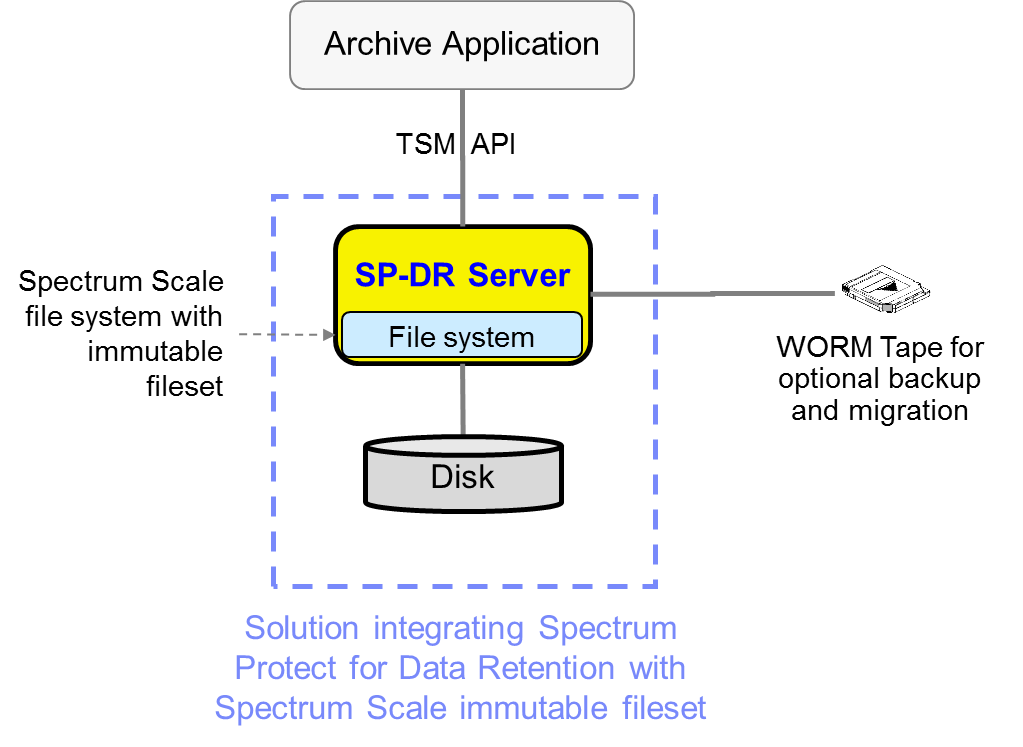
In IBM Spectrum Scale, you can copy information from one place to another, creating a carbon copy of the predecessor. This type of replication is known as data mirroring.
Data mirroring creates an identical copy of the data in the primary copy since it copies data in real-time. Information mirroring aids in the rapid recovery of critical data following a disaster. Data mirroring can be done locally or remotely at a different location.
Utilizing snapshots to protect file data
To retain the components of a file system or an impartial fileset at a specific time, a snapshot of the complete file system or impartial files can be generated.
A fileset screenshot is a complete inode spatial snapshot. Any snapshot of an individual fileset contains any dependent filesets encapsulated within that individual fileset. A snapshot of a reliant fileset is not possible.
Snapshots can be used in situations where multiple healing points are required. Before rebuilding the snapshot, make sure the file system is hung. Mounting a file system contains information on how to do so.
In today’s digital age, data is the lifeblood of organizations. It contains valuable information, insights, and intellectual property that drive business operations and decision-making. Therefore, ensuring the resilience and availability of data is of paramount importance. GPFS (General Parallel File System) data backups provide a robust and efficient solution for safeguarding data, enabling organizations to recover from data loss incidents and maintain business continuity. In this article, we will explore the concept of GPFS data backups, their benefits, and best practices for implementation.
Understanding GPFS
GPFS, developed by IBM, is a high-performance, shared-disk file system designed for managing and processing large amounts of data across multiple nodes in a cluster. It offers scalability, performance, and reliability, making it a popular choice for organizations with massive data storage requirements. Industries like finance, healthcare, research, and media, where swift and reliable data access is crucial, frequently utilize GPFS for its high-performance capabilities.
The Need for Data Backups
Data loss can occur due to various factors, including hardware failures, software glitches, human errors, cyberattacks, and natural disasters. Losing critical data can have severe consequences, including financial losses, operational disruptions, legal issues, and damage to reputation. Organizations must adopt a solid backup strategy to quickly and accurately restore data in case of data loss, effectively mitigating potential risks.
Benefits of GPFS Data Backups
- Data Resilience: GPFS data backups provide an additional layer of protection to ensure data resilience. By regularly backing up data, organizations can recover lost or corrupted files, minimizing the impact of data loss incidents. Backups act as a safety net, allowing organizations to restore data to a previous known good state.
- Business Continuity: Data is crucial for business continuity. GPFS data backups enable organizations to resume operations quickly by restoring critical data and minimizing downtime. With well-designed backup and recovery procedures, organizations can maintain productivity, customer satisfaction, and competitive advantage even in the face of unexpected data loss incidents.
- Compliance and Legal Requirements: Many industries have strict compliance and legal requirements regarding data retention and protection. GPFS data backups help organizations meet these obligations by ensuring that data is securely stored and available for retrieval when needed. This is particularly important in regulated industries such as finance, healthcare, and government sectors.
- Disaster Recovery: In the event of a natural disaster, cyberattack, or major system failure, GPFS data backups play a vital role in disaster recovery. By storing data backups in separate, geographically diverse locations, organizations can recover data and resume operations in alternative environments. This reduces the risk of data loss and ensures business continuity even in the most challenging circumstances.
Best Practices for GPFS Data Backups
- Define Backup Policies: Organizations should establish clear backup policies that outline the frequency of backups, retention periods, and prioritization of critical data. Different types of data may require different backup frequencies and recovery time objectives (RTOs) based on their importance and impact on business operations.
- A tiered backup strategy for GPFS data categorizes data by criticality and usage frequency, backing up critical and frequently accessed data more often, and less critical data at longer intervals. This tiered strategy optimizes storage resources and backup performance.
- Regularly Test Backups: It is essential to regularly test backups to ensure their reliability and accuracy. Testing involves restoring data from backups and validating its integrity and usability. By conducting periodic backup tests, organizations can identify any issues or discrepancies and take corrective measures promptly.
- Offsite and Cloud Backups: Storing backups in offsite locations or utilizing cloud-based backup solutions adds an extra layer of protection. Offsite backups protect data from physical disasters or localized incidents, while cloud backups provide scalability, accessibility, and redundancy. Offsite and cloud backups offer additional peace of mind and increase data availability.
- Encryption and Security: Data backups contain sensitive information, so it’s crucial to implement encryption and security measures to protect them from unauthorized access. Encrypting backups ensures that data remains unreadable to unauthorized individuals, even if compromised. Organizations should implement access controls, authentication mechanisms, and secure transmission protocols to safeguard backup data.
- Monitoring and Auditing: Regularly monitoring backup processes and performing audits help ensure the effectiveness and reliability of GPFS data backups. Monitoring can detect any backup failures or anomalies, allowing for timely resolution. Auditing ensures compliance with backup policies, verifies the integrity of backups, and identifies potential areas for improvement.
Conclusion
GPFS data backups are a vital component of data resilience and business continuity strategies. By implementing robust backup procedures, organizations can protect their valuable data, recover from data loss incidents, and maintain uninterrupted operations. GPFS, with its scalability, performance, and reliability, provides an excellent foundation for efficient data backups. By following best practices such as defining backup policies, implementing a tiered backup strategy, regularly testing backups, and ensuring security, organizations can ensure the availability, integrity, and recoverability of their data in the face of unforeseen events.
FAQs
What is GPFS Data Backup?
GPFS Data Backup refers to the process of creating copies of data stored within the General Parallel File System (GPFS) to protect against loss or corruption. This ensures data availability and integrity in case of unexpected events.
Why are GPFS Data Backups Important?
GPFS Data Backups are essential for ensuring data resilience and continuity. They provide a safety net against data loss due to hardware failures, system crashes, or malicious attacks, allowing organizations to recover vital information and resume operations promptly.
How often should GPFS Data Backups be performed?
The frequency of GPFS Data Backups depends on factors such as data volatility, business requirements, and recovery objectives. Generally, backups should be scheduled regularly to minimize the risk of data loss and maintain up-to-date copies of critical information.
What are the Different Backup Strategies for GPFS Data?
Various backup strategies can be employed for GPFS Data, including full backups, incremental backups, and differential backups. Each strategy offers distinct advantages in terms of backup speed, storage efficiency, and recovery capabilities.
Where should GPFS Data Backups be Stored?
GPFS Data Backups can be stored on different mediums, including onsite storage, offsite storage, tape libraries, disk arrays, or cloud storage platforms. Offsite storage is particularly important for disaster recovery purposes, ensuring data redundancy and geographic diversity.
How can GPFS Data Backup Processes be Automated?
GPFS Data Backup processes can be automated using backup management software or scripting tools. Automation streamlines backup scheduling, execution, and monitoring, reducing manual intervention and ensuring consistency in backup procedures.
What are Best Practices for GPFS Data Backups?
Best practices for GPFS Data Backups include regular testing of backups to verify data integrity and recoverability, implementing encryption for data security, enforcing access controls to restrict unauthorized access to backups, and maintaining comprehensive documentation of backup procedures and configurations. Following these best practices helps organizations optimize their backup strategies and enhance data protection capabilities.