So far, it’s all been about the storage of data, data in flight, data from IoT devices, etc. Let’s look at some traditional data processing methods and see how they work with modern database systems. Users’ model-based enquiries are manifested in a provided by individuals that are produced when the request payloads are initiated. Combining the data and business software has been the only actors who have collaborated to implement such data models. They work together to process users’ requests and store the data in dynamic data stores for future updates.
The degree of such actions among business applications ingesting data from all these distributed computing shared data storages is used to determine business continuity. Of course, if there are fewer of these actions, there is a greater chance that the firm will remain inactivity while waiting for new data to be acquired.
What depends on distributed computing?
The distributed computing paradigm above is intrinsically set up to potentially miss out on a huge opportunity to improve business continuity. A modification in the fixed database paradigm needs to close these gaps. The new enormous ingested information processing requirements necessitate the development of large-scale data processing that continually creates insight from any “data in-flight,” preferably in real-time. The persistence of intermediate calculated values in a temporary database server expects to keep a minimum to address storage access performance limitations.
This distributed computing blog looks at these new data processing approaches from real-time streamed ingestion and processing. It also goes into great detail on Dell Technologies’ offerings of similar types.
Distributed computing customers can use real-time streaming analytics technology by constructing their solutions based on open-source initiatives. It isn’t easy to mix and match such components to build real-time data input and processing systems. Stabilizing such networks in production contexts necessitate a wide range of expensive expertise. Dell Technologies offers proven reference architectures to satisfy desired KPIs on storage & compute capacities to make these implementations easier. The below sections offer a high-level concept of the real-time data streaming and various platforms for implementing these solutions. This blog compares and contrasts two Dell Ready Architecture solutions: Streaming Data Technology (previously known as Nautilus) or Real-Time Streaming architectures based on distributed computing Confluent’s Kafka ingestion platform.
Streaming data in real-time
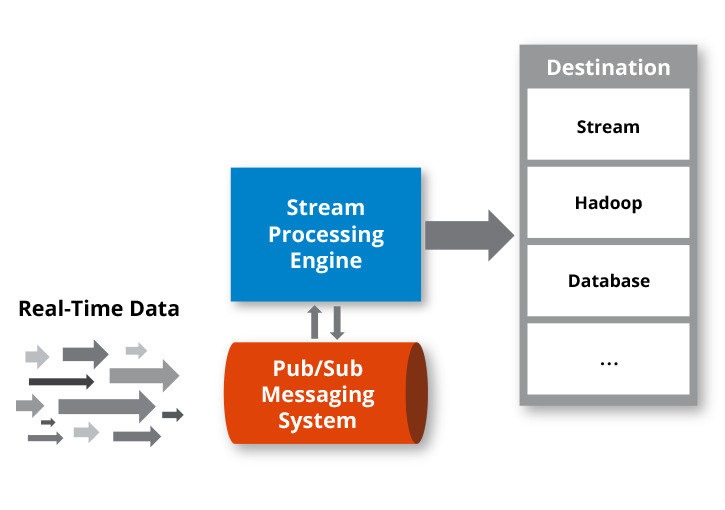
Image Source: Link
The concept of hard data streaming encompasses a lot more than just absorbing data directly. Many articles clearly define the compelling goals of a system that continuously ingests thousands of data events. Another founder of open-sourced Apache Kafka, Jay Kreps, has written an article that gives a complete and in-depth explanation of consuming real-time streaming data.
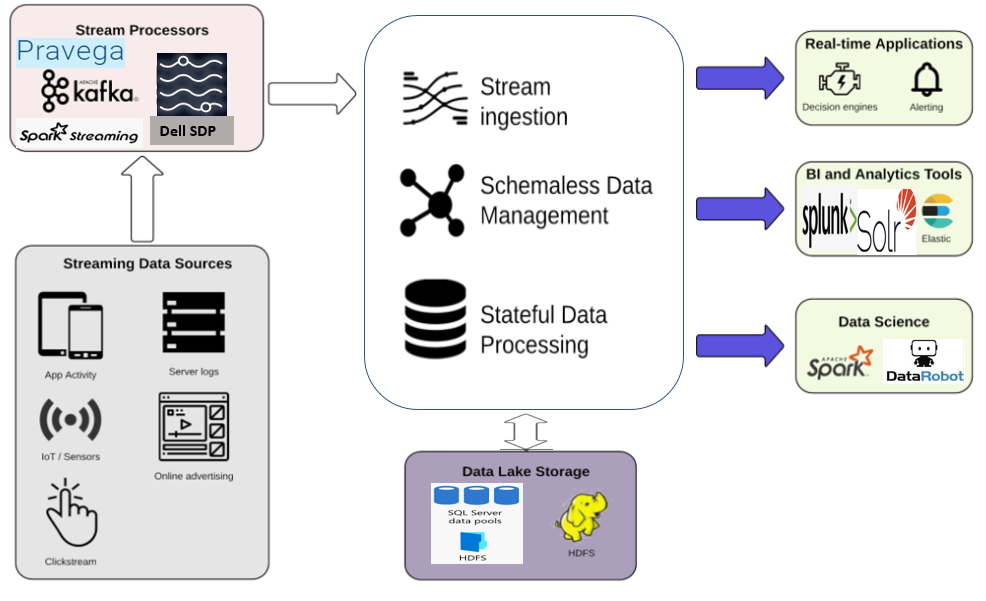
Distributed computing platforms for real-time streaming analytics
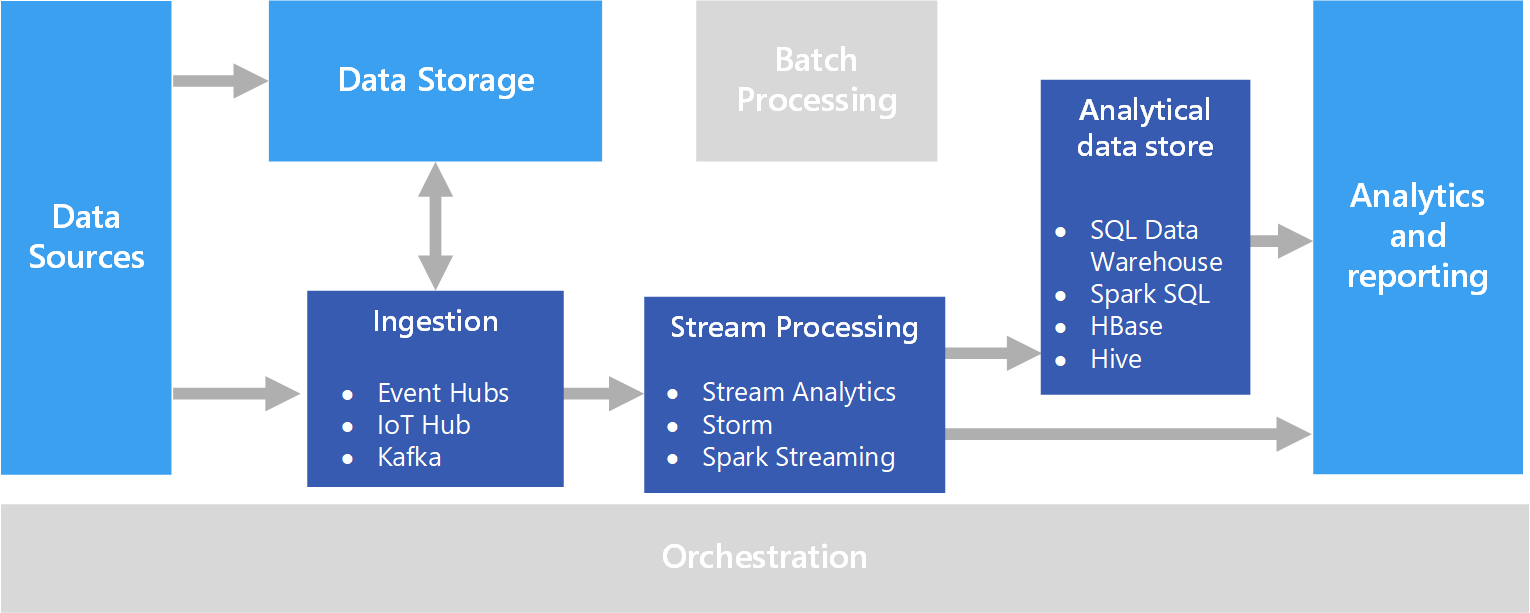
Image Source: Link
A complete final big data analytics solution must include the following features:
- Reduce the complexity of the data ingestion layer.
- Integrate with various components of the big data environment seamlessly.
- Develop insight-analytics apps with programming model APIs.
To access the processed data to visualization and business intelligence layers, provide plug-and-play hooks. Over the last several years, growth in real ingestion features has prompted the implementation of various integrated and holistic engines, each with its focused architecture. Streaming analytics engines have various capabilities, from micro-batching streaming data during processing to near-real-time performance to actual real-time processing. The consumed data could be anything from a binary event to a sophisticated event format. Dell Technologies’ Pravega & challenge posed Apache 2.0 Kafka are two examples of large size ingestion engines that can be effortlessly linked to open-source big data processing engines like Samza, Spark, Flink, & Storm, to mention a few. A variety of vendors offer proprietary implementations of related technologies. Striim, WSO2 Advanced Signal Processor, IBM Stream, SAP Action Stream Processor, & TIBCO Event Processing are just a few of these products.
A Dell Technologies plan for real-time streaming analytics
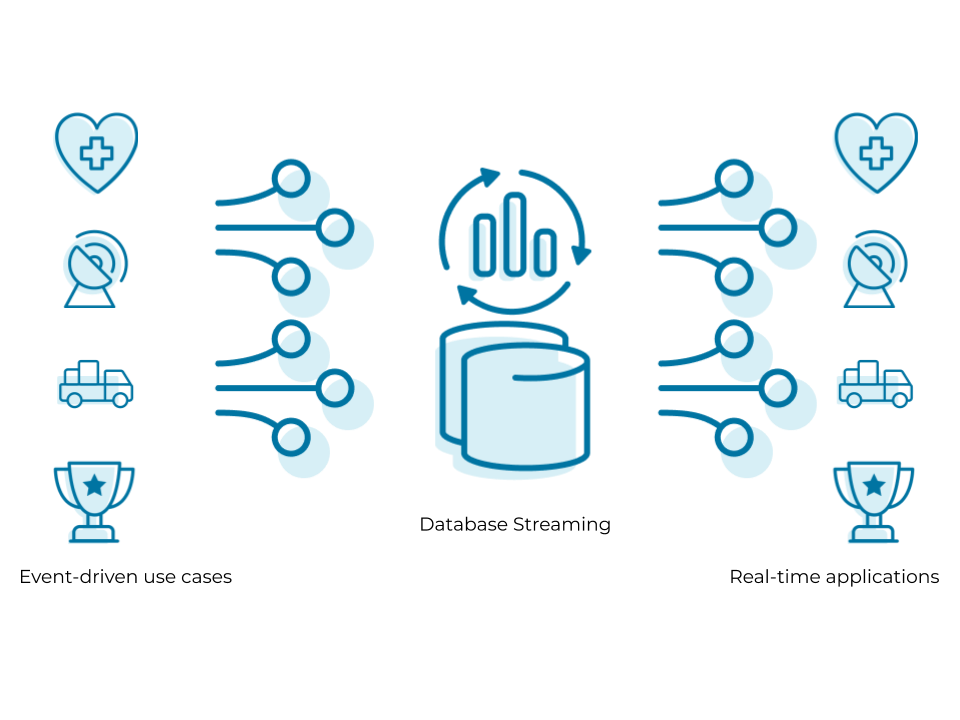
Image Source: Link
According to Dell Technologies, customers can choose between two options for implementing their real-time streaming infrastructure. The ingestion layer is created on Apache Kafka, and the default data stream processing engine is Kafka Stream Processing. The second approach is based on Pravega, an open-source ingestion layer, and Flink, the default simple data stream processing engine. And how are these products being leveraged to meet the needs of customers? Let’s look at some of the integration patterns that Dell Technologies’ real-time stream products can help with, including big data and partial pretreatment layers.
Patterns of real-time streaming and massive data processing
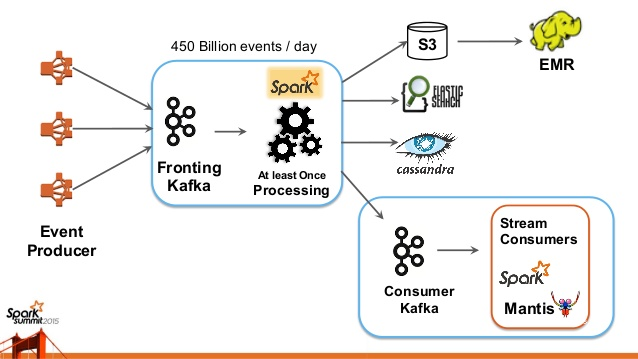
Image Source: Link
Customers use real-time streaming in various ways to fulfil their unique needs. This means there could be various ways to integrate real-time streaming solutions with the rest of the customer’s IT ecosystem. Customers can mix and combine a range of existing streams, storage, computation, etc., business analytics technologies to create a basic big data integration structure.
You can implement the Stream Processing layer in various ways, including the two following Dell Technologies solutions.
Confluent Enabled Platform for Hard Data Streaming from Dell EMC
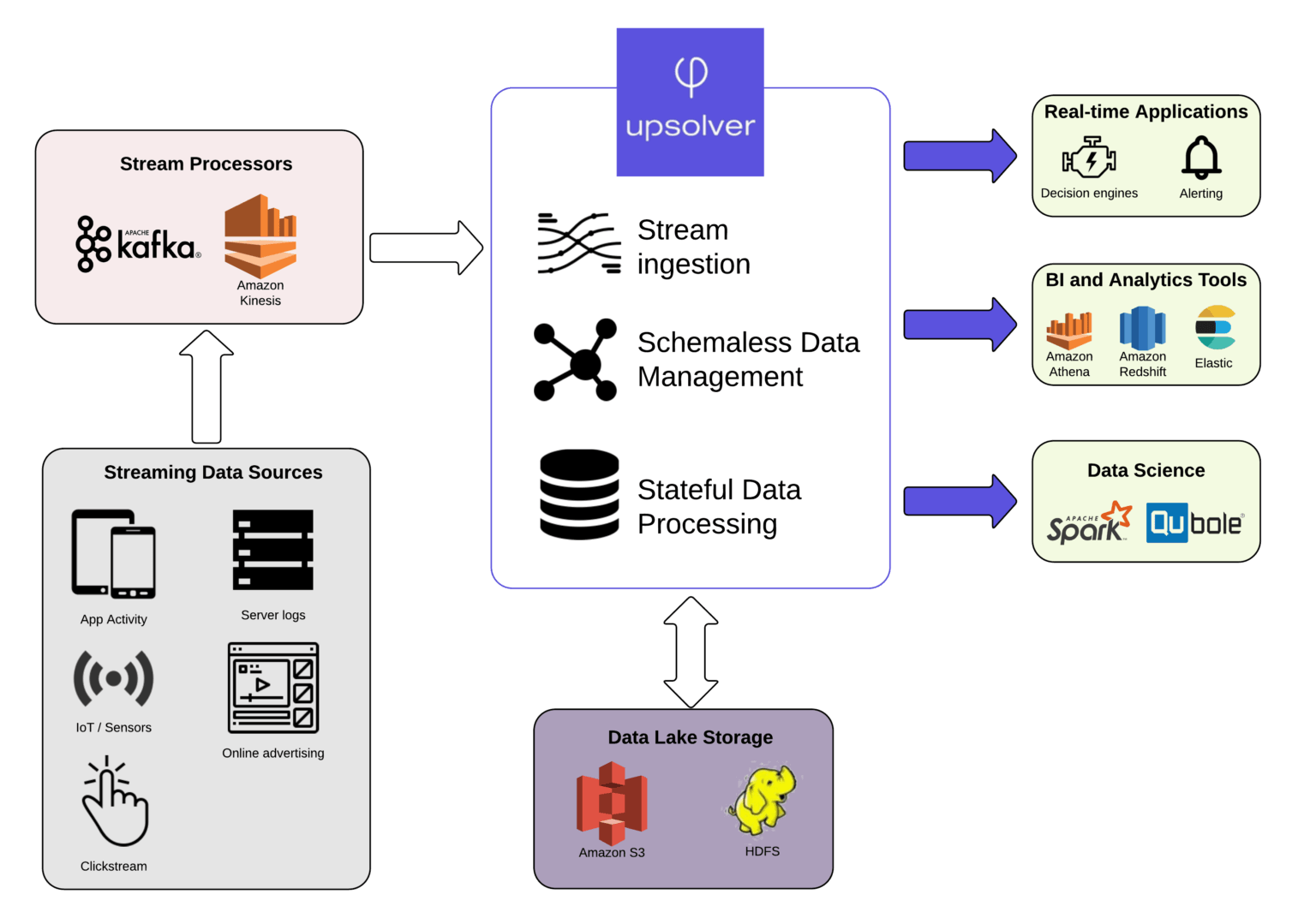
Image Source: Link
Apache Kafka is one of the best solutions, and it also includes Kafka Parallel Computation in the same package. Confluent offers and promotes the Apache Kafka distribution and the Confluent Enterprise-Ready Platform, which includes enhanced Kafka features.
Best Practices for Real-Time Streaming Data Ingestion
Real-time streaming data ingestion is becoming increasingly important in today’s digital world. The ability to quickly and accurately ingest, process, and analyze high volumes of data can be essential for many organizations. To ensure success with real-time streaming data ingestion, there are certain best practices that you must follow. First and foremost, it is important to choose the right infrastructure for your environment. This means selecting an architecture that is scalable, reliable, secure, and cost-effective.
Additionally, you should consider what type of data you will be dealing with as well as its size when choosing your architecture. Once you decide to, you can then move on to configuring proper security measures. It includes encryption or authentication protocols, to protect your data from unauthorized access or manipulation. Next up comes the actual ingestion process itself, which will involve setting up a system that can accept incoming streams of raw data from multiple sources simultaneously while also being able to filter out any wrong or irrelevant information before it enters into storage systems. For this task, tools like Apache Kafka often employ due to their scalability and robustness when dealing with large amounts of streaming data at once.
Scalability and Performance Considerations in Distributed Computing
When it comes to distributed computing, scalability and performance are two of the biggest considerations. Distributed systems can provide greater throughput than traditional architectures, but they also come with their own set of challenges. These include ensuring that the system is able to scale up or down as needed without any disruption in service, while simultaneously ensuring that performance remains optimal at all times. This requires careful design and implementation of load balancing techniques; proper management techniques for server resources such as CPU usage, memory utilization, network bandwidth requirements; and efficient communication protocols between nodes within a cluster or across clusters to ensure reliable information exchange. To maximize the potential benefits of distributed computing systems, developers should consider these factors carefully when designing applications for deployment in a distributed environment.
Handling Fault Tolerance in Real-Time Data Ingestion
Real-time data ingestion processes need to be designed with fault tolerance in mind. The process needs to be resilient and able to quickly recover from unexpected failures or system outages. This requires the use of technologies such as distributed messaging systems, databases that support replication, and streaming frameworks for handling stream processing tasks like windowed aggregation operations in a fault tolerant manner. Additionally, designing APIs for error handling can help the system handle errors gracefully without crashing or destabilizing other parts of the architecture. In addition to providing resilience against unexpected failures, it is important to periodically test the system under simulated failure conditions so that if an outage does occur in production it will not cause any long term disruption or loss of data integrity.
Monitoring and Managing Distributed Data Ingestion Pipelines
Distributed data ingestion pipelines are at the heart of big data technology. This allows different systems to share and process large amounts of data. Managing these pipelines can be a complex task as it requires understanding both the underlying architecture and the various components involved in transporting and processing the data. Good management practices need to include monitoring performance, setting up alerts for any abnormalities or potential issues, and ensuring that all nodes within the pipeline are running correctly.
Additionally, managing distributed datasets should involve keeping track of their lifecycle—from ingesting new raw sources into a staging area to transforming them into more useful forms for analytics or machine learning applications. Having an effective system in place will help ensure that you have reliable access to quality data when needed while also avoiding costly downtime due to problems with your infrastructure or processes.
Conclusion
Real time streaming data ingestion is an essential part of distributed computing. It also helps in understanding the architecture and tools needed can help ensure a successful implementation. Using existing technology like Apache Kafka or Flume allows developers to quickly start ingesting streams of real-time data by connecting them into various big data systems such as Hadoop for analysis. Furthermore, leveraging both message brokers and streaming architectures enables more efficient processing compared to traditional batch processing models. In summary, knowing how to effectively install real-time stream ingestion technology is essential in order to gain business insights from ever increasing amounts of real-time data sources.